brew/pip3 install ipython の違い
Homebrew を使って IPython を導入する際、brew install を使うやり方と、pip3 install をやり方の主に 2 つの方法があると思います。前者でやると IPython 起動時に PYTHONPATH を勝手に書き換えてしまうことが分かり、少しはまりました。そもそも ipython コマンドというのは bash script だったり、Python script だったり、環境によって違うのだということを知りました。
macOS 10.15.5 です。
Homebrew 環境の構築
これは書くまでもありませんが、https://brew.sh/の説明通りに次のコマンドを実行します。
$ /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)"
brew install ipython の場合(非推奨)
さて、IPython を入れたいのだから brew install ipython と単純にやると次のようになります。
$ brew install ipython
$ rehash
$ which python
/usr/bin/python
$ which python2
/usr/bin/python2
$ which python3
/usr/bin/python3
$ which ipython
/usr/local/bin/ipython
$ which pip
pip not found
$ which pip3
/usr/bin/pip3
つまり、macOS 標準の Python をデフォルトとして維持したまま ipython コマンドだけ入ります(実際には他にも色々と入りますが)。pip3 も入りません。
そして ipython の中身は次の bash script です。PYTHONPATH を勝手に書き換えてしまいます。
$ cat `which ipython` #!/bin/bash PYTHONPATH="/usr/local/Cellar/ipython/7.15.0/libexec/lib/python3.8/site-packages:/usr/local/Cellar/ipython/7.15.0/libexec/vendor/lib/python3.8/site-packages" exec "/usr/local/Cellar/ipython/7.15.0/libexec/bin/ipython" "$@"
これで PyROOT を使おうと思っても PYTHONPATH から ROOTSYS/lib が消えてしまい、おかしいおかしいと悩んでしまいました。これは bug じゃないかと思いますが、Homebrew の issue report をどこに上げるのかよく分からなかったので、放置しています。
brew install python を先にする場合(非推奨)
$ brew install python $ rehash $ which python /usr/bin/python $ which python2 /usr/bin/python2 $ which python3 /usr/local/bin/python3 $ which pip pip not found $ which pip3 /usr/local/bin/pip3
python3 コマンドが /usr/local/bin に入り、python と python2 は OS 標準です。この場合だと、pip3 も入りました。
$ brew install ipython
$ rehash
$ which ipython
/usr/local/bin/ipython
ipython の中身は同じです。
$ cat `which ipython` #!/bin/bash PYTHONPATH="/usr/local/Cellar/ipython/7.15.0/libexec/lib/python3.8/site-packages:/usr/local/Cellar/ipython/7.15.0/libexec/vendor/lib/python3.8/site-packages" exec "/usr/local/Cellar/ipython/7.15.0/libexec/bin/ipython" "$@"
pip3 install の場合(推奨)
$ brew install python $ rehash $ pip3 install ipython $ rehash
brew install python の後に rehash を忘れないようにしましょう。そうしないと、/usr/bin/pip3 が使われてしまいます。
cat `which ipython` #!/usr/local/opt/python/bin/python3.7 # -*- coding: utf-8 -*- import re import sys from IPython import start_ipython if __name__ == '__main__': sys.argv[0] = re.sub(r'(-script\.pyw|\.exe)?$', '', sys.argv[0]) sys.exit(start_ipython())
$ cat `which ipython3` #!/usr/local/opt/python/bin/python3.7 # -*- coding: utf-8 -*- import re import sys from IPython import start_ipython if __name__ == '__main__': sys.argv[0] = re.sub(r'(-script\.pyw|\.exe)?$', '', sys.argv[0]) sys.exit(start_ipython())
はい、こっちだと PYTHONPATH を勝手に書き換えませんし、bash ではなく Python です。こちらのやり方が推奨です。
Conda の場合
これは conda create で新しい環境を作ったときに入った ipython コマンドの中身です。また中身が違いますが、ほとんど一緒です。
#!/Users/oxon/anaconda3/envs/sstcam_root/bin/python # -*- coding: utf-8 -*- import re import sys from IPython import start_ipython if __name__ == '__main__': sys.argv[0] = re.sub(r'(-script\.pyw?|\.exe)?$', '', sys.argv[0]) sys.exit(start_ipython())
macOS Catalina/Monterey で PyVISA/PySerial を使う、に加えて初心者向けの丁寧な解説
macOS Catalina もしくは Monterey で PyVISA と PySerial を使うときの覚え書きです。PyVISA のほうは普通にやると、はまります。詳しい人向けの結論を先に書くと、NI-GPIB を先に入れないと NI-VISA が入らない、です。
※(2022/4/15 更新)Monterey の場合を加筆しました。
環境
- macOS Catalina 10.15.5
- Python 3.7.6(
brew install pythonで) - PyVISA 1.10.1(
pip3 install pyvisaで) - PySerial 3.4(
pip3 install pyserialで) - NI-GPIB 19.5
NI-VISA Runtime 19.0.0
macOS Monterey 12.2.1
- Python 3.7.7
- PyVISA 1.11.1(
pip3 install pyvisaで) - NI-GPIB 21.5
- NI-VISA Runtime 21.0.0
経緯
以前にこういう記事を書いたのですが、かなり情報が古くなってしまいました。当時は 32 bit と 64 bit が混在している時代で、Python も 32 bit だったり、National Instruments も Mac 用のドライバの配布が遅かったりと、苦労していました。 oxon.hatenablog.com Mojave から Catalina 環境に移行するにあたり、少し PyVISA ではまったので、記録に残しておきます。
うちの学生向けに書くので、比較的丁寧です。
VISA とは
VISA(Virtual Instrument Software Architecture) というのは、いろいろな実験室の計測装置を共通のソフトウェアで簡単に使えるようにしましょうという規格です。「査証」やクレジットカードの VISA とは関係がありません。
実験室にある計測装置の背面を見てみると、電源ケーブル以外に色々なケーブルを接続できることに気がつきます。古い機種だと RS-232C と呼ばれる規格の端子がついています(シリアルポートとも呼ばれます)。これは 9 本の剥き出しのピン(オスの場合)だったり、9 本のピンが差し込めるようになっているメスのポートだったりします。昔は計算機側にもこのポートが 2 つずつ付いていることが多かったのですが、今どきは付いていません。しかし実験室では、特にデータ転送速度を重視しない機器(低圧電源や回転ステージなど)ではいまだに使われることが多いです。
少し時代が経ち、オシロスコープのようにデータ量の多い装置では GPIB(IEEE の規格は IEEE 488)というケーブルの規格が使われるようになりました。最近はあまり見かけませんし、元々 GPIB 搭載の可能な機種でもオプション扱いのものが多かったと思うので、20〜30 年前くらいの高いデジタルオシロスコープなんかに付いていたりします(安いものにもついていたと思いますが、30 年前の安いものは既に廃棄処分されていると思います)。見た目がゴツくて格好いいやつです。写真はリンク先を参照。
最近だと、USB 端子がつく機種も増えました。むしろ新しい機種で USB すら付いていない製品やそんなものを販売する会社は、手を出さないほうがいいんじゃないかという気がします。USB 1.1(最大 12 Mbps)は低速の用途にも良いですし、USB 2.0(最大 480 Mbps)ならオシロスコープのようなデータ量の多い装置にも十分耐えられます。USB 3.0(最大 5 Gbps)以降を使用している機種は、2020 年現在、まだ多くないと思います。
オシロスコープのように通信量が大きい装置は、USB ではなく Ethernet ポートを備えたものもあります。機種によって 100 Mbps だったり 1 Gbps だったり 10 Gbps だったり、様々です。自分が実験で使う場合は USB 2 より Ethernet のほうが転送速度が早いため Ethernet を使いますが、この記事で説明するにはネットワークの設定の説明が面倒なのと、実験室ごとに設定がいろいろ変わるので、Ethernet の説明は省き USB 中心で説明します。
さて、VISA の話に戻ると、こういう異なるケーブルや通信プロトコルごとにソフトウェアを書き換えるのは面倒なので、一括で同じように扱えるようにしようというのが、VISA です。例えば何か計算機からコマンドを周辺機器に送るとき、もしくは周辺機器から計算機にデータが送られてくるとき、VISA 経由でやれば、どのケーブルやプロトコルを使用しているのかはほとんど気にしなくて良くなります。
PyVISA とは
PyVISA は、Python から VISA に対応した周辺機器とやり取りするための機能を提供してくれます。macOS Catalina に Homebrew で Python 3 を導入している場合、次のように pip3 コマンドで PyVISA をインストールします。
$ pip3 install pyvisa
後述する NI-GPIB や NI-VISA のインストールされた環境では、この PyVISA を使うことによって周辺機器と簡単に通信することができるようになります。次の例は、IPython から Tektronix の MSO4102B というオシロスコープに接続してシリアルナンバーなどの情報を得ているところです。
$ ipython In [1]: import visa In [2]: rm = visa.ResourceManager() In [3]: rm.list_resources() Out[3]: ('USB0::0x0699::0x041B::C022756::INSTR',) In [4]: usb = rm.open_resource(rm.list_resources()[0]) In [5]: usb.query('*IDN?') Out[5]: 'TEKTRONIX,MSO4102B-L,C022756,CF:91.1CT FV:v2.90 \n'
RS-232C での通信の場合は、ボーレート(baud rate)やデリミター(delimiter)などを気に掛ける必要がありましたが、VISA なら勝手にうまいことやってくれます。
デバイスドライバの部分は、PyVISA 自身はやっていません。macOS の場合、PyVISA は National Instruments(NI)の NI-VISA というデバイスドライバーをバックエンドとして使用しています。
PyVISA を macOS Catalina/Monterey に導入する手順
バージョン番号は適宜最新のもので読み替えてください。
0. Monterey の場合
macOS Monterey から、NI の機能拡張を使うには一手間かかるようになったので、事前にこの作業をします。この作業をすることで、macOS に NI を信頼できる開発者として認識させます。
まず Mac を再起動し、その際に Cmd-R を長押ししてリカバリーモード(recovery mode)に入ります。その後、Tools メニューから Terminal を開き、次のコマンドを実行します。
spctl kext-consent add SKTKK2QZ74
この SKTKK2QZ74は NI の developer ID です。
spctl kext-consent list
で、SKTKK2QZ74 が表示されるのを確認し、再起動しましょう(そのまま reboot と入力・実行すれば良い)。
1. NI-GPIB(NI-488.2)を入れる
PyVISA を使うには NI-VISA が必要で、NI-VISA を Catalina に入れるには NI-GPIB を先に入れる必要があります。リンク先から、Supported OS に MacOS、Version に 19.5 を選択してディスクイメージ(拡張子 .dmg)をダウンロードします。
NI-488.2 19.5.dmg を開くと NI-488.2 19.5.pkg が現れるので、これを開き、あとは指示に従ってインストールします。これは GPIB を Mac で使用するための NI 社製のデバイスドライバーです。再起動が必要です。
macOS 10.13 と 10.14 しか対応していないとなっていますが、10.15 で動作します。
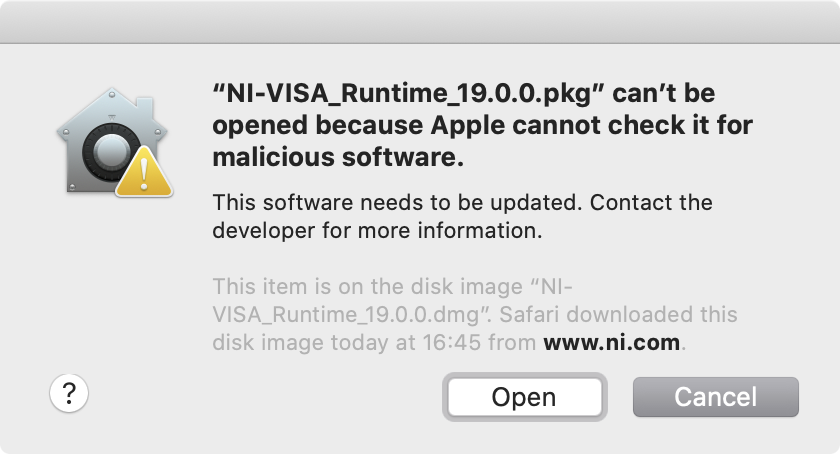
もしも .pkg を開けないとダイアログが出てきた場合、右クリックから開くようにすると次のダイアログが出るので、Open を選択してください。
2. NI-VISA Runtime を入れる
次に、NI-VISA を入れます。同様に Mac 版の 19.0 を入れます。この際、Included Editions は Runtime にすれば十分です。Full でも良いですが、PyVISA だけの使用であれば不要です。 www.ni.com
NI-VISA_Runtime_19.0.0.dmg を開くと NI-VISA_Runtime_19.0.0.pkg が現れるので、これも同様にインストールしてください。再起動は多分必要ありません。
3. PyVISA を入れる
Homebrew 環境の場合、pip から入れてください。Python 3 であれば pip3 です。
$ pip3 install pyvisa
4. インストールの確認
PyVISA とともに pyvisa-info というコマンドがインストールされるので、これが /Library/Frameworks/visa.framework/visa にある NI-VISA を自動的に検出できていれば成功です。
$ pyvisa-info
Machine Details:
Platform ID: Darwin-19.5.0-x86_64-i386-64bit
Processor: i386
Python:
Implementation: CPython
Executable: /usr/local/opt/python/bin/python3.7
Version: 3.7.6
Compiler: Clang 11.0.0 (clang-1100.0.33.16)
Bits: 64bit
Build: Dec 30 2019 19:38:26 (#default)
Unicode: UCS4
PyVISA Version: 1.10.1
Backends:
ni:
Version: 1.10.1 (bundled with PyVISA)
#1: /Library/Frameworks/visa.framework/visa:
found by: auto
bitness: 64
Vendor: National Instruments
Impl. Version: 19922944
Spec. Version: 5244928
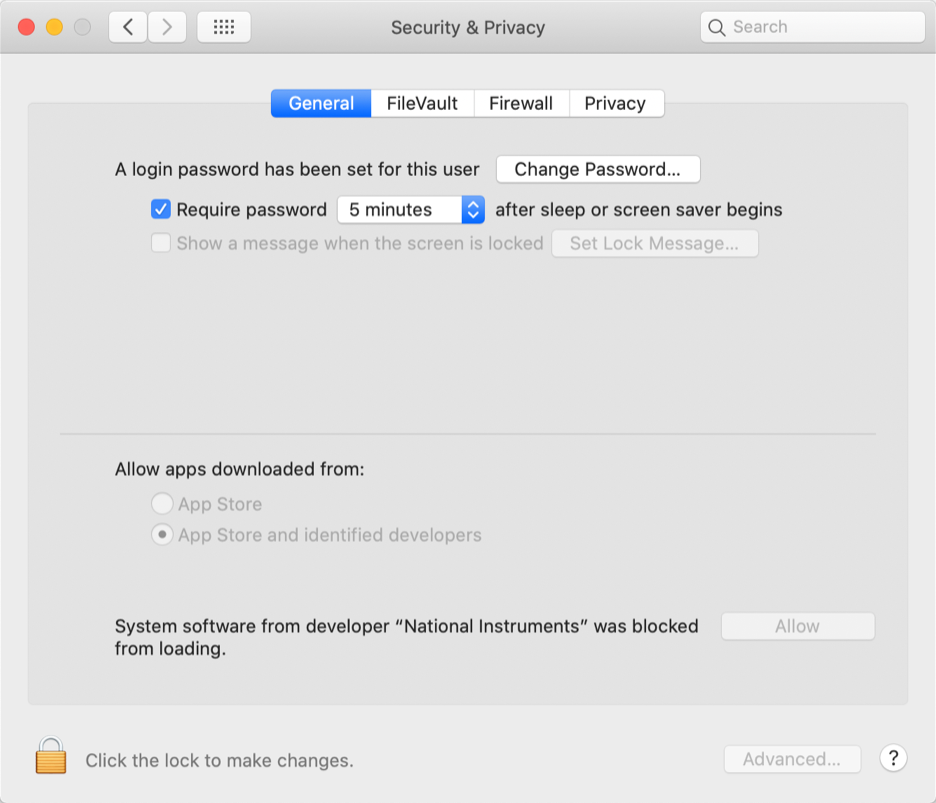
もし abort したというエラーが出る場合、System Preferences の Security & Privacy で NI 製のソフトウェアがブロックされていないか確認してください。もしこの画像のようにブロックされている場合、鍵を外して Allow を押して、許可してやりましょう。
5. 動作確認
先述したコマンド例の繰り返しになりますが、VISA に対応しているはずの適当な実験装置を USB ケーブルで Mac に接続し、次のように真似して *IDN? コマンドを送信してみましょう。普通の装置は後述の SCPI というコマンド体系に準拠しているはずで、ほとんどの装置は *IDN? コマンドに対して機種情報を返します。
$ ipython In [1]: import visa In [2]: rm = visa.ResourceManager() In [3]: rm.list_resources() Out[3]: ('USB0::0x0699::0x041B::C022756::INSTR',) In [4]: usb = rm.open_resource(rm.list_resources()[0]) In [5]: usb.query('*IDN?') Out[5]: 'TEKTRONIX,MSO4102B-L,C022756,CF:91.1CT FV:v2.90 \n'
これで、Tektronix の MSO4102B-L という機種でシリアルナンバー(S/N)C022756 のものが繋がっているというのが分かります。ファームウェアのバージョンがおそらく 2.90 なのだと思います。
SCPI
さて、周辺機器の接続情報だけ得ても面白くないので、*IDN? 以外の SCPI について調べましょう。Wikipedia の記事にもあるように、SCPI は実験室で使うような測定装置とやり取りするための標準的なコマンドの文法の規格です。メーカーが異なっても、例えば Tektronix でも Keithley でも岩通でも、SCPI で制御できる装置は似たようなコマンドで動作させることができます。
例えば上述の Tektronix のオシロスコープの電圧表示範囲を変更してみましょう。文法を調べるには、例えば「MSO4102 programmer's manual」などで Google 検索すると PDF が出てくるはずです。次のページが出てきたので、PDF をここから入手しましょう。
マニュアルを読むと、このような説明が出てきます。
CH<x>? Returns vertical parameters for the specified channel
それでは、実際にやってみましょう。ここで注意するのは、<x> の部分は適切な値に置き換えよという意味です。? が最後についているのは、問い合わせのコマンドということです。つまり、返り値があります。
In [6]: usb.query('CH1?') Out[6]: '0;10.0000;"No probe detected";"";1.0000;"V";50.0000;"Other";0.0E+0;0.0E+0;1.0000E+9;DC;0.0E+0;0.0E+0;0;-2.9600;1.0000;"V";50.0000;""\n'
この読み方はマニュアルを参照するとして、例えば縦軸の分割幅は 1.0000 V であり、オフセットが -2.9600 V だということが分かります。カップリングは DC で終端は 50.0000 Ω です。
次に、電圧のオフセットを変更してみましょう。マニュアルによると、文法は CH<x>:OFFSet <NR3> および CH<x>:OFFSet? です。ここで小文字は省略可能という意味です。また <NR3> は 2.0E-3 などの指数表示を意味します。(<NR1> は整数値、<NR2> は小数です。)
In [15]: usb.write('CH1:OFFS 1.23E-1') Out[15]: (18, <StatusCode.success: 0>) In [16]: usb.query('CH1:OFFS?') Out[16]: '123.0000E-3\n' In [17]: voffset_ch1 = float(usb.query('CH1:OFFS?')[:-1]) In [18]: voffset_ch1 Out[19]: 0.123 In [20]: usb.write('CH1:OFFS %.2E' % voffset_ch1)
動作確認時を除いて、実際にプログラム中に書くときは省略せずに全て書くことをお勧めします。コマンドの可読性が増すからです。
次に波形を取得してみましょう。簡単のため、データフォーマットは ASCII にします。
In [31]: usb.write('WFMOutpre:ENCdg ASCii') In [32]: usb.write('DATA:SOURCE CH1') In [33]: data = usb.query('WAVFRM?') In [34]: data[:250] Out[34]: '2;16;ASCII;RI;MSB;"Ch1, DC coupling, 1.000V/div, 4.000ms/div, 1000000 points, Sample mode";1000000;Y;LINEAR;"s";40.0000E-9;-20.0000E-3;0;"V";156.2500E-6;29.6960E+3;123.0000E-3;TIME;ANALOG;0.0E+0;0.0E+0;0.0E+0;27648,27904,27392,27648,27648,27904,27648'
あとは、マニュアルを読んでこのデータを波形情報に戻してみましょう。
PySerial
USB 端子を持っていても、VISA に対応していない機器があります。その多くは USB 端子の後ろに USB to Serial converter と呼ばれる、USB とシリアル通信(RS-232C)を変換するチップが搭載されています。このような機器は PyVISA ではなく PySerial を使って制御します。
また、USB 端子ではなく RS-232C 端子しかない機器もあるでしょう。これには、USB-RS232C の変換ケーブルを使用します。変換チップには様々なメーカーのものが存在しますが、FTDI 社製のものが一般的です。また FTDI 製であれば macOS でも Windows でも Linux でもデバイスドライバーのインストールなしに動作しますので、例えば Buffalo のこのケーブルは確実に動作します。
1.0m ブラックスケルトン BSUSRC0610BS")
Mac に FTDI 製のチップを持つ周辺機器、もしくは FTDI 製チップの使われている変換ケーブルで RS-232C の機器を接続したときは、/dev/ 以下にデバイスファイルが作成されます。
例えば Keithley 社製のある機器の場合、FTDI のチップが使われているため次のように表示されます。表示されるデバイスファイル名はチップのシリアルナンバーにしたがって異なるものになります(Mac の場合)。
$ system_profiler SPUSBDataType
(略)
USB 3.0 Hi-Speed Bus:
Host Controller Location: Built-in USB
Host Controller Driver: AppleUSBXHCI
PCI Device ID: 0x1e31
PCI Revision ID: 0x0004
PCI Vendor ID: 0x8086
Bus Number: 0x14
USB HS SERIAL CONVERTER:
Product ID: 0x6001
Vendor ID: 0x0403 (Future Technology Devices International Limited)
Version: 4.00
Serial Number: FT123456
Speed: Up to 12 Mb/sec
Manufacturer: FTDI
Location ID: 0x14100000 / 1
Current Available (mA): 500
Current Required (mA): 44
$ ls /dev/tty.usbserial*
/dev/tty.usbserial-FT123456
PySerial を入れると、同様に SCPI のコマンドで制御することができるようになります。
import serial keithley = serial.Serial(port="/dev/tty.usbserial-FT123456", baudrate=57600,timeout=1,writeTimeout=1) keithley.write('*RST\n') keithley.write(':SENS:FUNC "VOLT"\n') keithley.write(':SOUR:FUNC VOLT\n') keithley.write(':OUTP ON\n')
ここで、RS-232C の装置の場合は baudrate という値の設定をその機種ごとに揃えて必要があります(今の例の場合、57600)。装置のマニュアルに必ず書いてあるはずですので、読むようにしましょう。また使用する改行コードも機種ごとに異なるため、今の場合は \n を使用していますが、これもマニュアルで確認してください。
Anaconda で ROOT 入れたり
Anaconda 環境に ROOT を入れるときのメモ。1 年前に Mojave でやったときとちょこちょこ変わっているので、2020 年 6 月現在の以下の環境を想定。
まず、Mac 用の Anaconda を落としてくる。 https://repo.anaconda.com/archive/Anaconda3-2020.02-MacOSX-x86_64.sh
適当に答えて進める。
$ chmod +x Downloads/Anaconda3-2020.02-MacOSX-x86_64.sh $ ./Downloads/Anaconda3-2020.02-MacOSX-x86_64.sh
自動的に .zshrc に Anaconda の設定が書き込まれるのが好きじゃないので、自分の場合は関数で括って好きなときにAnaconda 環境に入るようにしている。
conda_init(){
# >>> conda initialize >>>
# !! Contents within this block are managed by 'conda init' !!
__conda_setup="$('/Users/oxon/anaconda3/bin/conda' 'shell.zsh' 'hook' 2> /dev/null)"
if [ $? -eq 0 ]; then
eval "$__conda_setup"
else
if [ -f "/Users/oxon/anaconda3/etc/profile.d/conda.sh" ]; then
. "/Users/oxon/anaconda3/etc/profile.d/conda.sh"
else
export PATH="/Users/oxon/anaconda3/bin:$PATH"
fi
fi
unset __conda_setup
# <<< conda initialize <<<
}
4.8.3 に update する。
$ conda_init (base) $ conda update -n base -c defaults conda
好きな環境、例えば sstcam_root という環境を作る。このとき、-c conda-forge で channel を指定する必要あり。ROOT はここにあるので。
(base) $ conda create -n sstcam_root root -c conda-forge (base) $ conda activate sstcam_root (sstcam_root) $ which root.exe /Users/oxon/anaconda3/envs/sstcam_root/bin/root.exe (sstcam_root) $ root root [0] .q
以前は MacOSX10.9.sdk とかを落としてくる必要があったのだけど、今は要らなくなった。なので、Anaconda 側で Xcode についてくる SDK を勝手に環境変数に設定してくれる。これは base のときは空っぽで、次のように ROOT 環境のほうだけ。10.15 が指定されている。
$ conda_init (base) $ echo $CONDA_BUILD_SYSROOT (base) $ conda activate sstcam_root (sstcam_root) $ echo $CONDA_BUILD_SYSROOT /Library/Developer/CommandLineTools/SDKs/MacOSX.sdk (sstcam_root) $ ll $CONDA_BUILD_SYSROOT lrwxr-xr-x 1 root wheel 15 Mar 25 11:24 /Library/Developer/CommandLineTools/SDKs/MacOSX.sdk -> MacOSX10.15.sdk
これで、ACLiC も問題なく動く。ACLiC を動かすためにも、以前は SDK を自分で用意する必要があった。
(sstcam_root) $ root root [0] .x aho.C+ Info in <TMacOSXSystem::ACLiC>: creating shared library /Users/oxon/./aho_C.so
Anaconda で入れるものではない library を CMake で build するとき、引数を追加する必要がある。
docs.conda.io
ここを読むと、次のようにやる必要があるらしいのだけど(これは clang が Anaconda 環境のものが使用されてしまうため)、
(sstcam_root)$ cmake ../source -DCMAKE_INSTALL_PREFIX=$CONDA_PREFIX -DCMAKE_OSX_SYSROOT=$CONDA_BUILD_SYSROOT
実際には次のコマンドでちゃんと動いた。CMake のバージョンによるのかもしれない。
(sstcam_root)$ cmake ../source -DCMAKE_INSTALL_PREFIX=$CONDA_PREFIX
SYSROOT の ROOT は ROOT と関係ない。
この環境で例えば他に Python 関係のものを追加したい場合、conda-forge から入れるようにする必要がある。
(sstcam_root) $ conda config --env --add channels conda-forge (sstcam_root) $ conda install scipy astropy matplotlib tqdm pandas numba cython scikit-learn
Studio.app と LDraw を使って LEGO 風のイベントディスプレイをスーパーカミオカンデ用に作る
同業の中の人がこんな企画をされていました。
スーパーカミオカンデのイベントディスプレイ作成用データの公開を始めました。ニュートリノや陽子崩壊のシミュレーションデータを元に、あなた独自のイベントディスプレイを作ってみませんか?データには光電子増倍管の位置座標と光の量や時間の情報が含まれています。https://t.co/YTqHhOTHAP pic.twitter.com/PZVXqA0rLJ
— 神岡宇宙素粒子研究施設 (@Kamiokaobs_pr) May 29, 2020
あくまで一般向けのものであって、同業者が手を出すものではないと思うのですが、Python + matplotlib よりも ROOT だと早いよ、というのを言いたくなってしまったので、大人気ないことをしてしまうわけです。
先生、できました!5 行でした! https://t.co/KGrrINGi2c pic.twitter.com/I57wO4CvQA
— OKUMURA, Akira(奥村 曉) (@AkiraOkumura) May 30, 2020
さて、以前から LEGO ブロックで物理関係のことをやってみたいなとずっと思っていて、また LEGO の 3 次元データを扱うためのファイルフォーマットの 1 つである LDraw というものを最近知りました。LDraw のフォーマットは非常に簡単なので、これを使うとイベントディスプレイに使えます。
www.ldraw.org
また Studio.app という LEGO(風の)ブロック用の 3D ソフトウェアもあることを知り、これで LDraw をインポートできるということもわかりました。じゃあ、これらを組み合わせるとスーパーカミオカンデ(SK)のイベントディスプレイを LEGO 風にできるわけです。
www.bricklink.com
本当は SK ではなくて、自分のやっているチェレンコフ望遠鏡アレイ(CTA)のイベントディスプレイで遊ぶべきなのですが、同業の中の人の企画にまず乗っかってみようかな、と。
さて、結果です。
ROOT で 5 行で作る場合
$ root
root [0] TNtuple nt("nt", "nt", "ch:pe:t:x:y:z")
root [1] nt.ReadFile("Downloads/sample/multirings.0001.000015.csv")
root [2] nt.SetMarkerStyle(20)
root [3] nt.SetMarkerSize(0.5)
root [4] nt.Draw("z:y:x:pe", "", "col")
ROOT + Python で LDraw に出力したもの
$ ./sk2lego.py Downloads/sample/multirings.0001.000015.csv > event.ldr

LDraw の形式は、こんな感じです。1 に続けて、色番号、座標と回転行列の要素、そして部品番号です。簡単ですね。
1 36 x y z Rxx Rxy Rxz Ryx Ryy Ryz Rzx Rzy Rzz 4073.dat
まあ、これだけだと実際に立体に組むことはできないので、東大 LEGO 部の作品に組み込むと格好良さそうな気がします。

sk2lego.py の中身です回転行列を使う必要があるので、それは ROOT を呼んでいます。
愛知・岐阜県内 329 人の感染経路を可視化してみた
愛知・岐阜県内の感染経路図5/4 18時現在
— OKUMURA, Akira(奥村 曉) (@AkiraOkumura) May 4, 2020
・5/4新規感染者:愛知 +3 岐阜 0
・うち感染経路不明・未確定:愛知 +1
・図の読み方は図中左上の凡例を参照
・最新情報はこのスレッドに追加するのでそれをRTしてください
・作図方法と雑感は blog 参照https://t.co/Izc7zR8cWR pic.twitter.com/oYxOahF6VM
記事のタイトルは、9 年前の自分の記事からの「インスパイア」です。あの頃は、放射線量の時間変化や、空間分布を作っていました。福島県に親戚が住んでいたからです。いつでも逃げられるように、定量的な判断基準を持つための資料が必要でした。
oxon.hatenablog.com
雑感
今回の新型コロナウイルスでは、誰から感染するかも分からないし、逆に感染させてしまうかもしれないし、日本中、世界中のどこに行っても「逃げる」というのは困難です。自分一人が感染を防いでも社会全体の流れを止めることはできず、全員が同じように感染防止を目指さないと、逃げたくても逃げられないという、大変困難な状況です。我が家は自主的に保育園の利用を停止したり、小学校の始業式をサボったりしていますが、うちだけやったところで社会の流れを止められるわけもなく、焼け石に水と思いながら行動しています。
さて、毎日コロナのニュース、特に名古屋大学のある愛知県のニュースを観ていても、「本日は新規感染者が XX 人」とか「YY で起きた集団感染の濃厚接触者」とか 、そんな断片的な情報ばかり入ってきて、全然可視化できない。何が起きているか、頭の中で考えられない。どの集団感染がまだ続いているのか収束したのか把握し続けられない。合計感染者数の時間変化のヒストグラムを眺めても、はたして愛知はどういう状況かというのがちっとも分からない。そういう不満がありました。そこで、9 年ぶりに手を動かしてみることにしました。
図から分かること
愛知県は初期に感染者の急増があったのですが、その後増加が緩やかになりました。これを合計感染者数や、日毎の新規感染者数のヒストグラムで眺めていると何が起きているか見えませんでした。
(専門家や追いかけている人たちは知っていることでしょうが)今回の図で、2/14 と 2/29 に始まった初期の集団感染 2 件(スポーツジムとデイサービス)が関係者の努力で収まり、3 月上旬から感染経路不明の「孤発」事例が出続けているということが、よく見えてきました。感染防止や対策が徹底されていなかった頃の集団感染は仕方がないとして、やはり孤発事例が頻発し始めた時点で強い対策を取らないと、一気に広がるのだということが分かります。
3 月末からは岐阜県でも孤発事例が増え始め、愛知県警や岐阜シャルムの集団感染を除けば、感染経路不明のものが毎日 5〜10 件出るようになってしまいました。これは東京の 2 週間前と変わらない状況なので、自粛ムードの強くはなかった東海エリアでは、この先 2 週間で増え続けると覚悟する必要があります。
愛知の人口でも初期クラスターから感染経路不明の増大へ、という流れがはっきり見えるのですから、東京・大阪の大都市圏では、やはり「クラスター対策をすれば大丈夫」なんていうのは専門家の認識が甘かったということかと思います。もちろんクラスター潰しと追跡調査をするのは絶対に必要ですので、関係者の努力は大変ありがたいことです。しかし、あまりに感染力が強すぎた。追えない事例が多数出てしまう。それが今回の COVID-19 の大変なところであり、専門家ですら対策できると過信してしまった原因なのではないでしょうか。
このような感染の拡大は、おそらく愛知や岐阜に限ったことではないでしょう。まだ感染者の少ない小中規模の都市でも、気持ちを緩めていると孤発事例が徐々に増えていき、「あれ、もしかして危ない?」と思い始めた頃には後手後手の対応に回ってしまうということが起き続けるでしょう。
可視化したいもの、やりたいこと
- 感染者数の時間変化(それだけなら他にいくらでも転がっている)が終えること
- 集団感染なのか孤発事例なのかの切り分けができること
- 感染経路不明の事例の時間変化が一瞥して分かること
- 帰国者や外国籍が分かること
- 個々の集団感染がどのように広がり、収束したのかどうか、今も拡大し続けているのか分かること
以上の条件を満たすにはどうすれば良いかを検討し、普段は CERN の ROOT というデータ解析ライブラリを使うのですが、今回は Graphviz を使うことにしました。
www.graphviz.org
実際にどうやるか
Graphviz は複数のノード(node)をエッジ(edge)で接続し、うまいことグラフを描画してくれるソフトウェアです。ここで言う「グラフ」は、ネットワーク図などグラフであり、数学用語のグラフです。
何百人もいる感染者をノードとして配置し、感染者同士の接触をエッジとして表現するのは、手動でやるのは困難です。少なくとも何週間かは毎日この作業を継続する必要があると判断し、Graphviz で自動化することにしました。簡単に自動化できるだろうと踏んでいたのですが、実際は手動での微調整でかなり作り込んでやる必要がありました。
Graphviz をそのまま使うのではなく、CSV ファイルを Python で読み、Python 内で graphviz モジュールを利用することにしました。
多数の感染者情報を自治体発表の HTML や PDF から収集するのは非常に大変なのですが、東海 3 県に限っては中京テレビが機械可読性の非常に高いデータ整理をしてくれていました。原発のときは文科省や福島県の測定データを自分自身や有志の多くの方のご協力で Google Spreadsheet に手入力し、可視化も自分でするという作業をしていたので大変だったのですが、中京テレビのお陰で今回はその点、とても楽です。
www.ctv.co.jp
Graphviz で苦労したところ
日付を縦方向に揃える
Graphviz の基本的な考え方は「自動で全てのノードをいい具合に配置する」です。そのため、細かいノード位置の調整を人間がして、エッジだけ自動的に描かせるという思想にはなっていません。しかし今回は、ある日付に陽性確定した感染者を時系列で並べたいため、同じ陽性確定日の感染者は縦に整列させる必要があります。
そこで、今回は subgraph と rank という機能を使って、同じ陽性確定日の感染者は無理やり横位置を揃えることにしました。この場合、Graphviz は横位置を揃える作業は死守してくれるようです。例外なく、ちゃんとノードを揃えてくれました。
好きな場所に文字列を置けない
凡例や注意書きなど、グラフ中に多数のテキストを配置する必要がありました。しかし、調べた限りではそのような機能がありません。また Graphviz の描画エンジンとして dot を使用する場合、座標の指定なんかもできないようです(いくつかの描画エンジンを選べるが、前述の rank は dot で使える)。
そのため、図中の様々なテキストは、多数のノードを追加するという無理やりな手法をとっています。加えて、ノードの中に書き込むテキストは、テキスト中心位置とノード中心位置が同じになります。そうすると文字列を左揃えにすることができなくなるため、全角スペースを多数挿入するという荒技を使っています。
s.node('author', label=' ' * 25 + 'データ出典:https://www.ctv.co.jp/covid-19/person.html\n' + ' ' * 28 + '作成:@AkiraOkumura(名古屋大学 宇宙地球環境研究所 奥村曉)', shape='plaintext', fontsize='40', height='2.5')
ノードの縦位置が自動配置されてしまう
「自動配置されてしまう」と Graphviz に文句を言うのは、それが設計思想なので筋違いなのすが、今回の図では愛知県と岐阜県で区分けしたかったため、この自動配置には大変困りました。左→右で進むグラフの場合、追加したノードは下から上に並ぶようです。ただし追加した順通りになるわけではなく、グラフ形状にしたがって自動配置が Graphviz が最適と思うやり方で行われます。
そうすると、愛知県の感染者ノードの中に岐阜が混じってしまったり、その逆も起きます。そこで、手動にて非表示のエッジを多数追加することで、自分の意図した場所に無理やり置くことができるようになります。見えないエッジを追加することで、それらが接続するノードを近接した場所に置こうと Graphviz が機能するためです。しかしこれでも、自分の意図したものに近づくだけであって、Graphviz の挙動を完全に制御することはできません。
graph.edge('aichi134', 'dummy2020-03-19', style='invis') graph.edge('aichi145', 'dummy2020-03-23', style='invis') graph.edge('aichi151', 'aichi152', style='invis') graph.edge('aichi155', 'aichi152', style='invis') graph.edge('aichi155', 'aichi151', style='invis')
エッジ以外の線が描けない
これも Graphviz の設計思想として、そんなものは必要ないのは明らかですが、エッジ以外の線を自由に描くことができません。今回の場合、愛知と岐阜の県境を滑らかな線で描きたかったのですが、これも非表示のノードを多数配置しそれを点線のエッジで接続することで、無理やり実現しました。県境が滑らかでなくガタガタしているのはこれが原因です。
matplotlib などと連携できない
本当はヒストグラムなどを matplotlib かなんかで描いて、Graphviz の結果も一緒に並べるなんてことをやりたかったのですが、Python の graphviz モジュールはそれ単体の世界で閉じているので、できませんでした。
エッジが多すぎると作図が発散する
集団感染が発生した場合、多くの感染者ノード同士を何本ものエッジで接続すると、描画結果が大変な場合になることがありました。具体的には岐阜県の飲食店シャルムの集団感染なのですが、ここをエッジで接続するのは諦めました。

")
- 作者:カミュ
- 発売日: 1969/10/30
- メディア: ペーパーバック

- 作者:ジャレド ダイアモンド
- 発売日: 2013/07/12
- メディア: Kindle版
Gist にきったない Python コードを置いておきます
人に見せるような綺麗なコードではないのですが、Graphviz を使う例として、誰かの役に立つかもしれません。
gist.github.com
Twitter のサムネイル用

オンライン講義の経験談
新型コロナウィルスの影響により、Zoom 等を利用した大学講義のオンライン中継をこの 4 月から始める大学教員の方が多くいらっしゃると思います。僕はこれまでに同様のオンライン中継を 4 年間継続してきました。どのような問題が発生するか、どういう心構えでいれば良いか、個人的な体験を少しまとめておきます。
1. 行なった講義の形態
- データ解析とプログラミングの講義 ROOT 講習会 2019 · akira-okumura/RHEA Wiki · GitHub
- 90〜120 分/回のオンライン講義、合計 5〜6 回/年を 4 年間継続(2016〜2019 年のそれぞれ 4〜6 月)
- 対象者は学部 4 年生と修士 1 年生
- 板書なしの全てスライド(PDF は事前配布)
- 名古屋大学の学生 10〜15 名程度は対面で、その様子と Mac のスライド画面を全国 10〜15 大学に中継(リモート接続含め、合計参加者 90 名程度)
- マイクとカメラは、スライドを上映している Mac を使用

2. 感じた問題点
2-1. まるで壁に向かって喋っているようだ
同じ部屋に 10〜15 名程度の学生がいたものの、講師の側からはオンライン接続先の学生の顔が見えません。講師側の映像さえ学生に届いていれば良いようにも思いますが、実際やってみるとそうではありません。
通常の講義では、目の前にいる学生と頻繁に目を合わせることによって、直前に話した内容が理解されているかどうか、講義の進度が早すぎないかどうか、そういうものを講師側が読み取ることができます。例えば首を傾げている学生がいたり、相槌を打っている学生がいたり、板書に対してノートの追いついていない学生がいたり、そういったかなりの情報を講師側は教壇から得ています。
しかし、相手の顔や様子が分からないとなると、ひたすら気にせず一方的に喋り続けるか、もしくは 3 分に 1 回くらい「ここまで大丈夫?よく分からないところある?」といちいち学生に聞き続ける必要があります。この際、これも通常の講義で相手の顔色さえ伺えれば大丈夫かどうか雰囲気で分かるものですが、オンライン接続だと「大丈夫です」と全員が声を上げてくれるわけでもなく、10 秒程度待っても質問がなければ次へ進むという、非常にテンポの悪い進め方になります。
2-2. 質問のタイミング
名古屋大学の物理学科では、対面の講義でもなかなか質問の手が上がらないのですが、これがオンライン接続となるとさらに質問へのハードルが上がるようです。まず、ネットワークには必ず遅延が発生します。そのため、学生が「今だ」と思って質問したとしても、講師側は既に次の話題を話し始めていて、互いにタイミングの狂うことがあります。
また、相手側のマイクが入っていない、音声入力が小さくて聞き取れないといった、海外とのオンライン会議に慣れた研究者でもいまだに発生する問題が、不慣れな学生には頻発します。
加えて、リモートで参加している学生は教室の雰囲気が分かりません。他の学生は分かっているのかどうか、自分が分からないのは音声が途切れ途切れで聞き逃しただけだからではないかなど、通常の講義に比べると質問に対する心理的障壁が高くなると思われます。
2-3. チャット
気軽に質問をしやすくするためチャット画面でも質問を受け付けましたが、まず、こちらの期待するタイピング速度を学生は持っていません。向こうがゆっくりキー入力している間に、講義はどんどん進んでしまいます。
また、チャットでの質問は短文になりがちなため、結局こちらから「こういう意味?」と聞き返す必要がある場合がほとんどで、音声で質問してもらった方がトータルで早いということがありました。
加えて、講師の側は講義を行うのに集中しています。チャット画面をにらめっこしているわけには行かないため、質問されていても気がつかないということもあります。
2-4. 音声、映像が途切れる
これはもう技術的に仕方ない話ですが、音声や映像が途切れたり、途中で会議アプリケーションを立ち上げ直したり、なぜか会議に入り直すことができなくなったりという問題が毎週、毎年発生しました。研究者同士の会議でもこれは発生するので、不慣れな学生相手ではもうどうしようもないと思います。
2-5. ホワイトボードが映らない
スライドだけで講義するにしても、たまにホワイトボードに手書きで説明する必要がどうしても出てきます。この場合、カメラがどこの輝度に合っているかに注意しないといけません。プロジェクターのスクリーンに輝度があっている場合、その横にあるホワイトボードに字を書いても、おそらく配信先の学生には暗すぎて見えないでしょう。講義室にいる人間の眼のダイナミックレンジと、中継カメラのダイナミックレンジは全く異なるということを意識する必要があります。
またスライドではなく黒板でやる場合、カメラの解像度が十分あるか、解像度が十分あったとしても、ネットワークが不安定な相手先でブロックノイズが発生せずに綺麗に見えているかを気にする必要があるでしょう。
また身振り手振りで何かを説明する場合、自分がカメラからはみ出してしまうかもしれません。ホワイトボードもカメラに収まっている視野外にまで文字を書いてしまうかもしれません。
2-6. スライドの行ったり来たり
十分よく練って作ったスライドでも、「さっき説明した通り…」のように、何枚か前のスライドに移動したり、「後で説明するつもりでしたが…」と先に進んだりと、行ったり来たりすることはよくあります。この場合、講義室では即座に移動した先のページが見えるわけですが、接続先の学生の手元ではすぐに画面が切り替わっていないかもしれません。音声だけは途切れずに流れた場合、何ページ目が講義室で示されているのか分からなくなる場合があります。
2-7. 講義室の学生の声が拾えない
参加する学生が全員リモート接続であれば良いですが、通信環境の準備できない一部の学生などは大学の講義室で講義に参加すると思われます。この場合、ノートパソコン内蔵のマイクは講師側に向かっていますので、教室の後ろの席から学生が質問した場合、講師には質問が聞こえるけれどマイクは音を拾わないという状況になります。この場合、講師が「今 XXX という質問が講義室で出ました」と復唱する必要があります。
2-8. 冗談が通じたかどうか、反応が分からない
まあ、これは想像がつくと思います。悲しいです。
3. 改善案
3-1. 質問しやすい環境づくりと質問の練習
初回の講義のときに、マイクが問題なく動いているかの動作確認も含め、質問の練習をさせてみてください。また、じゃんじゃん質問して良いのだ、講義を質問で止めても良いのだ、自分だけ音声が途切れたかもしれないなんて気にしなくて良いのだ、ということを学生に伝えてください。
3-2. スライド PDF は前日までに配布
スライドでやる場合、必ず PDF にして前日までに配布し、講義の開始までに先にダウンロードするように指示してください。50 MB くらいのファイルに最近は簡単になってしまうため、講義の直前に配布したり、講義中に URL を教えたりすると、PDF をダウンロードし終えない学生が出てきます。
3-3. スライドの注意点
必ずページ番号を各ページに入れてください。何ページ目を開いているのか、必ず分かるようにしましょう。また PowerPoint や Keynote でアニメーションは一切使わないでください。たまに切り替わる静止画を送るのはオンライン会議ソフトは得意ですが、動画を上手に送れるとは期待しないでください。また配布 PDF ではアニメーションは再生できません。間違っても PowerPoint や Keynote のファイルのまま学生に配布しないように。
3-4. いつもよりゆっくり
通常の講義の 1.5 倍くらい時間をかけて進む必要があると思ってやってください。音が途切れたり、質問のやり取りは、通常の講義よりかなり時間を食います。
3-5. 接続テストを何回も
院生とかに協力してもらって、事前に接続テストをしっかり行なってください。
3-6. 録画する
途中で接続できなくなったり音声や画面が途切れてしまう学生が必ず出ます。これを学生の責任とするのはあまりに酷なので、そのような学生が後で視聴できるよう、講義を録画してください。
3-7. 質問の声の大きさ
講義室で質問する学生には、マイクで音を拾いやすいよう、大きな声で質問するよう、事前に依頼してください。
3-8. 心を強く持つ
相手の顔が見えない状態で講義をするのは、かなり心の折れる作業です。僕はメンタル強い方だと思いますが、ここ数年間で一番辛い仕事でした。
3-9. 板書に相当するもの
手元の PC のスライドを画面共有する場合、iPad と Apple Pencil などを活用して、板書に替わるものを用意しておくと便利かもしれません。その場合、PC と iPad の両方から同じ会議に参加する形が便利ではないかと思います。
全部黒板を使っての講義の場合、それを全て iPad に置き換えるというのは難しいかもしれません。
3-10. 講義室ローカルの雑談で盛り上がらない
学生側が活発な講義の場合、質問や講師側の雑談から、少し話が脱線して講義室内にいる人だけで雑談が発生する場合があります。これはリモート参加者からすると苦痛でしかありません。マイクで音を十分拾えず、また雰囲気も分からないからです。ついつい講義室にいる学生に向かって話してしまいがちですが、リモート接続の学生が主たる聞き手だという意識を 90 分持続しましょう。
論文の読み方入門
対象読者
この記事はうちの研究室に入ってくる学部 4 年生や修士 1 年生に向けたものです。論文の読み方について説明しますが、どの分野でも当てはまることかは分かりません。また研究室や指導教員ごとに、色々と考え方があると思います。
大学院に進学すると「論文を読め」と言われます。しかし読んだことのないものを読むのは大変なものです。「読め」と言ってくる教員も、自分たちが若かりし頃に論文を読むのに苦労したことを忘れてしまっている場合もあります。論文とはそもそも何なのか、論文をどうやって読んだら良いか、毎年新入生に説明するのもこちらも大変なので、記事にまとめます。
論文とは
大学院生や研究者が研究をすると、その結果を論文と呼ばれる形態にして世界に発信します。どのような立派な研究をしても、論文という形で誰でも読める状態にして発表しない限り、その結果が人の目に触れることはないからです。研究結果を論文にまとめて発表するというのが、その研究の一つのゴールだと言えます。
論文として発表する以外に、国際会議や学会などでの講演、特許の取得という方法もあります。しかし口頭発表などをするだけでは、その場にいた人にしか研究成果を伝えることはできません。そのため、いつでも誰でも世界中から研究結果を見ることができるよう、論文にして後世に記録を残すのです。
何か新しい研究を始める前に、すでに誰かがその研究をやっていないか調べる必要があります。これを先行研究を調べると言います。研究というのは先人が積み上げた科学成果の上に立って、さらに科学を発展させていく作業ですので、誰かが過去にやったことを繰り返しても意味がありません。また、研究をする上で先人の失敗や問題点を知っておくのも、自分の研究を円滑に進める上で重要なことです。
論文は数ページから数十ページの文章です。これを複数まとめて掲載する媒体を論文誌とか学術誌とかジャーナルと呼びます。有名なものだと、Nature とか Science とか Physical Review Letters があります。このような論文誌は週刊誌などと同じように、複数をまとめて号 (volume) という単位で発行します。また、その号の中で通しのページ番号を振られます。ある特定の論文を指すには、著者名、雑誌名、号、ページ番号、発行年を並べます。例えば、次のように書きます。
Akira Okumura, Astroparticle Physics 38, 18–24 (2012)
論文の種類
論文には大きく分けて 3 つの種類があります。
査読論文
論文出版の流れは大雑把に次のようになります。
- 研究して結果が出る
- 論文にまとめる (論文を書きながら研究することもあります)
- 論文の出版社に投稿する
- 通常はレフェリー (査読者) から査読コメントというものが返ってくるので、これに従い論文を改定して出版社に送り直す (ここで掲載拒否 = reject される場合もあります)
- 論文が受理 (accept) される (受理されない場合もあります)
- PDF としてオンラインで公開される
- 紙媒体に印刷されて、場合によっては大学の図書館に収まる (オンラインしか存在しない論文誌もあります)
業績として見なされるものは通常これです。うちの業界では、査読のない論文というのは滅多にありません。
上記の Okumura (2012) の例だと、論文本体は http://dx.doi.org/10.1016/j.astropartphys.2012.08.008 から HTML や PDF で入手可能です。
国際会議プロシーディングス
多数の研究者が集まって研究成果を発表する国際会議が世界中でたくさん開かれています。これら会議、特に規模の大きいものでは (うちの分野だと ICRC や SPIE や IEEE や VIC など)、プロシーディングス論文 (proceedings paper) というものを発表者が書く場合があります。これは会議で発表した研究内容を数ページの比較的短い論文として執筆し、会議に参加しなかった人でも読めるようにするものです。
ただし、査読論文 (対義語としてフルペーパーと呼ぶこともある) に比べ、研究の途中結果の場合が含まれる場合が多々あります。また、すでにどこかで査読論文として出し終えたものの焼き直しだったりする場合もあります。逆にプロシーディングスとして発表されたのに、いつまで待っても査読論文として最終結果の出てこない研究もあったりします。
このような論文は、査読のあるものもあれば査読のないものもあります。特に査読のないものは、その品質があまり保証されません。査読があっても、普通の査読論文に比べると査読がしっかりしていない場合も多いので、うちの分野では総じて品質が高くありません。そのため、「論文を読め」と指導教員に言われた場合、査読論文を指していることが多いでしょう。
一方、途中経過であったり質が高くなくとも、プロシーディングス論文から研究の最新情報を得られる場合はたくさんあります。特に何年もかかる装置開発などの場合、途中経過であってもプロシーディングス論文から多くの情報が得られる場合が多いです。必要に応じてきちんと読みましょう。
arXiv
https://arxiv.org/archive/astro-ph
査読論文はレフェリーとのやり取りで半年や 1 年を費やすこともあるため、最新の研究を世界中に伝えるには必ずしも良い方法ではありません。そのため、論文を書いたらすぐに世の中に出したい場合、arXiv というサービスを使うのがうちの業界では一般的です。
arXiv は書いてすぐのものを査読なしで投稿することができるため、査読論文として出版される最終版と中身が異なるものが多くあります。特に理論の論文だとその割合は高くなります。もし論文を読むときに arXiv でその論文を見つけた場合でも、出版社の出している最終論文がないかを確認し、最終版を読むようにしてください。
実験系の論文は最終的な結果や数字以外を出したくないので、特に大きな実験グループの場合、査読論文として受理された後に arXiv に載せる場合が多いです。
先述の論文例だと、https://arxiv.org/abs/1205.3968 がそれです。
論文へのアクセス
多くの出版社は営利企業が運営しており、読者からの購読料を集めない限り運営ができません。そのため論文を読むためにはその対価を支払わなくてはいけません。図書館に置かれている論文誌は、図書館が出版社から購入したものです。
しかし学生や研究者がオンラインで PDF 論文を読みたい場合、論文ごとに何千円も支払うのは非効率です。そのため、多くの大学や研究機関では多数の出版社とオンラインアクセスのための契約をしています。その大学のネットワーク内から論文にアクセスすると接続元の IP アドレスを確認し、それが契約を結んでいる大学のものであれば、論文を無料で (実際は大学が何億円も払って購読料で契約している) 読むことができます。自宅などからアクセスすると、金を払わないと読めないと表示されるでしょう。
しかし近年になって、国民の税金でやった研究成果を見るために営利企業にさらに国民が料金を支払わないといけないのはおかしいとか、商業出版社の寡占化 (大学の支払う購読料が値上がりし続ける) が問題視されています。そのためオープンアクセス (open access) と呼ばれる、誰でもどこでも論文を読めるように PDF が公開されている論文誌も多く出てきました。
慣れないうちの論文の読み方
進学して最初の頃は、背景となる最新研究、これまでの過去の研究の経緯、どのような実験・観測装置があるかといった知識が圧倒的に不足しています。量子力学や電磁気学の勉強は何十年も前に構築された基礎物理ですので、これだけを一生懸命勉強してきても残念ながら論文は読めないのです。
また、大学入試程度の英語力 (例えばセンター試験の英語で 95% の得点率) では論文を素早く読むことはできません。業界特有の英語が使われていたり、日本語で物理を勉強したために対応する英単語を知らない、また入試に出てこないような英単語も多く出てきます。これに前述の知識不足が重なるのですから、最初は短い論文であっても読むのに苦労すると思います。
ですので、「読め」と言われて「読めませんでした」となるのはごく自然なことなので、あまり悲観的にならないでください。しかしそれを乗り越えないと論文は読めるようになりませんし、多読と慣れと勉強でどうにかなりますので、諦めずに読んで下さい。
最初は読めないのは当たり前なので、「自分が英語が苦手だからだ」と思うことなく、わからない部分は教員や先輩にどんどん質問をしましょう。とても簡単な英単語でも、その物理背景を知らないとさっぱり意味が分からないことは多々あります。
例えば僕が M1 のときにスーパーカミオカンデの論文を読んだのですが、「electron-like event」のような言葉が全く理解できなかったのを覚えています。単語自体は簡単で直訳すれば「電子風事象」ですが、何が「風 (ふう)」なのか理解不能でした。これは背景となる反応プロセスを理解していないため、英語としては意味が理解できても、物理として意味が分からないのです。
論文を読む上での要所
論文を読んできた学生に僕がいつも尋ねるのは、「で、この論文は何がどう面白いの?」ということです。論文というのは何かしらの科学成果が書かれているわけですから、それが科学的に重要な (= 科学として面白い) ものであれば、何が重要な成果なのかが必ず書かれているはずです。つまり面白い話のオチ (論文の結論) が書かれているはずです。
しかし政治を理解していないと時事ネタの冗談のオチが理解できないように、背景となる知識の不足や英語の読解力不足があると、その論文の面白さを理解できません (論文自体がまったく面白くないという場合もありますが)。ですので、自分がその論文をちゃんと読めているかどうかは、その論文の面白さが理解できたかで判断するのが簡単です。
次に、なぜこの論文が書かれたか、研究が行われたのかを説明できるかを確認しましょう。これは研究の背景が理解できているかの確認になります。
そして、論文に出てくる図の一つ一つから何が言えるのか、なぜその図がその論文には必要なのかを説明してみましょう。論文はある動機や仮説、研究背景から始まり、何かしらの結論に辿り着くように書かれています。論文中の図表は、その結論に進む論理展開を支持するために必要な材料なのです。ですから、なぜその図があるのか、その図から何が言えるのかを理解できているというのは、その論文の論理展開を追うことができたということです。
論文によっては不必要な図があったり、論理展開がそもそもおかしい場合もあるので、論文がおかしいと思ったら、論文に書かれていることを鵜呑みにせず、自分の考えも大切にしましょう。
少し慣れたら
論文を数本読んでみて、書かれていることをなんとなく理解できたら、その論文で引用 (citation) されている論文にも目を通してみましょう。例えば今読んでいる論文がある天体の観測論文だった場合、他の望遠鏡による観測の論文や、同一の望遠鏡でも過去に観測した例などが引用されているはずです。
一つの論文には何十もの引用がされているのが普通なので、全てを通読する必要はありません。ただ、引用されている論文の中身を知らないと、読んでいる論文の動機自体がそもそも理解できない場合が多々あります。そのような場合、引用されている論文の概要 (abstract) や図だけでも目を通してみましょう。
Abstract というのは、その論文に何が書かれているかを短くまとめた、通常 1 段落の文章です。論文の先頭には必ずこれが書かれており、論文全体を読む必要があるか、面白いかどうかはこれを読んで判断することがほとんどです。
その他の情報
ADS
論文情報へのリンクとして論文誌そのものや arXiv へのリンクではなく、ADS での情報がやり取りされることがあれます。ADS とはハーバードや NASA の運営する天文関係の論文データベースです。宇宙線関係の論文もほとんどのものが網羅されています。先述の論文だと https://ui.adsabs.harvard.edu/#abs/2012APh....38...18O/abstract に情報が掲載されています。
DOI
DOI とは、書籍や論文などの出版物に固有の ID を振る仕組みです。出版社が買収や倒産で URL が変更になったりしても大丈夫なようになっています。先述の論文の DOI は 10.1016/j.astropartphys.2012.08.008 であり、この先頭に http://dx.doi.org/ をつけることで論文のページに飛ぶことができます。