論文を剽窃されて 1 年半かけて撤回させた話
剽窃については、こっちの記事を読んでください。
oxon.hatenablog.com
1. 経緯
2021/7/4 にある国際会議のプロシーディングス論文(以降、論文 A)を読んでいたところ、そのイントロに見覚えのある複数の文章を見つけ、さらにページを進めると自分が作った図と全く同じ、ただしその著者がいちから作り直したものが掲載されていました。
お、僕の論文を剽窃している他の論文を見つけてしまったぞ。どうしよう、このボタンは押してみたい。
— OKUMURA, Akira(奥村 曉) (@AkiraOkumura) July 4, 2021
この論文に cite されているなというのは前から知っていたのだけど、ちょっと調べ物をしていて読んでみたらイントロでとんでもない量の剽窃が、という。https://t.co/mvyGZbAKgZ
— OKUMURA, Akira(奥村 曉) (@AkiraOkumura) July 4, 2021
この論文 A は自分の査読論文(論文 B、copyright は Elsevier)および国際会議のプロシーディングス(論文 C、copyright 不明、おそらく自分)を引用しており、堂々と論文 B、C の文章と図を剽窃しているのでした。論文 A の著者は自分の全く知らない研究者で、ヨーロッパのある小国の大学のシニア研究者(肩書は教授職ではない)のようです。
自分の所属する研究所や研究部門では毎年「剽窃防止講習会」のようなものを修論を書き始める M2 対象に実施しており、その講師を僕がやっています。そのため、学位論文以外にも自分たちの分野で実際にどのような事例があるかというのを取り上げてみたいという下心もあり、行動に移ることにしました。
ありがたく今後の剽窃防止講習会で使わせていただく
— OKUMURA, Akira(奥村 曉) (@AkiraOkumura) July 4, 2021
2. 問い合わせ前半(単独行動)
2021/7/4 同日
出版社(AIP Publishing)の問い合わせ窓口のウェブフォームから剽窃行為の指摘とそれへの対応を求めました。自動返信メールの類が一切届かなかったのですが、ウェブから送信した後の表示画面のスクショは保存したため、送信に問題はなかったはずです。
— OKUMURA, Akira(奥村 曉) (@AkiraOkumura) July 4, 2021
2021/11/24
そのまま通常業務に戻ってほったらかしになっていたのですが、出版社からは一切返事がなかったため、また同じ窓口から問い合わせを送りました。
大量に剽窃されてるんだけど対応してほしいと某出版社に何ヶ月も前に連絡したのに返事が来ていないことを思い出した。同じ窓口からまた連絡した。
— OKUMURA, Akira(奥村 曉) (@AkiraOkumura) November 24, 2021
「数ヶ月前に論文 A の剽窃行為について問い合わせをしたが一切の返信がその後ないので、コンタクト先を教えてくれ」という内容です。help@scitation.org にメールが届くようです。
同日、help@aip.org の Customer Experience Specialist を名乗る担当者から confproc@aip.org を Cc して返信が来ました。主な内容は次の通りです。
We have forwarded your inquiry to our Conference Proceedings Team.
さらに 1 時間後に confproc@aip.org の「Editorial Assistant, Conference Proceedings」を名乗る担当者から主に次の内容のメールが来ました。
Can you please provide a detailed synopsis of this case so that we may begin our investigation?
2021/11/25
詳細を教えろという出版社側からの指示だったため、論文 A の剽窃箇所、論文 B と C の剽窃された箇所をハイライトし、PDF にまとめて返信しました。剽窃箇所は以下の内容です。
- 論文 B から連続する 2 行相当(2 段組論文)
- 論文 B から連続する 7 行相当
- 論文 B から 1 行相当
- 論文 B から連続する 3 行相当
- 論文 B から連続する 2 行相当
- 論文 B から連続する 2 行相当
- 論文 B から連続する 3 行相当
- 論文 B から図およびそのキャプション
- 論文 C から連続する 4 行相当(2 段組論文)
- 論文 C から連続する 3 行相当
- 論文 C から 1 行相当
- 論文 C から連続する 2 行相当
- 論文 C から連続する 4 行相当
合計すると 2 段組で 33 行相当が少なくとも剽窃されているので、3 分の 1 ページ程度相当と、図ですね。
2021/12/1
同担当者から返信。調査を開始したとのことです。ここまでは順調。
We have opened an investigation into this matter and will update you with our findings as soon as possible.
2021/12/10
論文 A〜C を 1 つの PDF にまとめたものではなく、元のバラバラのものを送るようにとの指示。別にそれで作業は進まないだろうと思いますが、それで調査が止まるのも嫌なので送信しました。
Following up on our previous correspondence, I would like to ask if you could please provide PDFs of articles [2] and [3] (rather than the concatenated single file) to assist us in investigating this case.
2022/1/25
PDF を送り直したものの、それに対する受領のメールも進捗報告もないため、こちらから担当者に状況の問い合わせを送りました。
2022/1/26
同担当者から以下の返信。
AIP Publishing is committed to the integrity of the peer review and publishing of scientific works. Our Journals and Editors are members of the Committee on Publication Ethics (COPE) which provides support and guidance on all aspects of publication ethics. As such, we must follow COPE protocol in handling this case which may take some time, but rest assured that we are working to get this resolved as soon as possible.
どうやら Committee on Publication Ethics(COPE)という組織があるようで、AIP はこのメンバーのためそこの手続きに従う必要があるとのことです。
2022/7/2
時間がかるのは分かりますが、半年が経っても何も音沙汰がないため再び問い合わせをしました。
2022/7/8
返信は一応来ます。
This is to acknowledge that your email has been received and we will get back to you with a response as soon as possible.
2022/9/6
再び沈黙が訪れたたため、また問い合わせをしました。論文 A はある国際会議のプロシーディングスであったため、もしこれ以上返信がないのであれば、その会議の運営側にこちらから連絡を入れると通告しました。
2022/9/17
時間がかかるという返信がまた来ます。
Many thanks for your email; we certainly understand your concerns. Please be assured that this case is currently under investigation. We work as quickly as possible to resolve cases, however, please note that they are sensitive and take time. Therefore, we are unable to provide a timeline for when a particular case will be resolved by. We sincerely appreciate your patience while we investigate and thank you for allowing us the time to review the matter.
3. 問い合わせ後半(エディターを巻き込む)
2023/2/10
どのような状況なのかを AIP に問い合わせ続けても何も状況が分からず進捗報告もないため、論文 A の出版された国際会議プロシーディングスのエディターに問い合わせることにしました。研究業績のしっかりしていると思われる教授 2 名がエディターでした。この時点で、このエディターには既に AIP から連絡が入っていると期待していたのですが、一切の連絡が行っていなかったようです。
2023/2/14
エディターから返信が来ます。しかしなぜかここで、論文 A の著者自身が Cc されます。あくまで著者に対しては匿名で扱われると当然視していたため「匿名にしてくれ」とは一切メールに書かなかったのでこちらの落ち度ではあるのですが、ともかく著者にこちらの名前と動きが漏れます。
このメールには、さらに著者の上司と思われる人たち数名が含まれていました。ちなみに 2 人のエディターも著者やその上司らと同じ大学の所属です。建物も同じらしく、居室も 20 m 離れているだけとのこと。
返信の内容は、確かにこれは多くの文章が剽窃されているので、エディターとして AIP にサポートレターを書くよ、これは科学に対する重大な問題である、というものです。
2023/2/15〜3/10
自分とエディター 2 名のみでのやり取りをしました。著者自身や、その上司から一切の返信がないのは不誠実でありダンマリを決め込もうとしているのだろう、のようなメールがエディターから来たり、AIP もずっとまともな返信をしてこないのは「indefinite postponement is a polite form of rejection.」だと書いてきたり、こちらを支持してくれてるのかどうなのかいまいち分からない文脈でしたが、ともかくエディターから AIP にメールを書いてくれるということになりました。
この際、AIP とのやり取りは全てエディターに送っています。
2023/3/9
エディター 2 名を Cc し、AIP に自分から再びメールを送りました。
1. 状況を知らせよ
2-a. もし AIP がこれを剽窃と認めるのなら論文を撤回せよ
2-b. もし AIP が剽窃だと認めないとしても、論文の改訂が必要であると考えるのならば、著者にそうさせよ
2-c. 何の対応も必要ないと AIP が考えるのならば、その理由を説明せよ
という要求をあらわにメール中に書きました。
2023/3/10
エディターから「we fully support Dr. Okumura」という内容のメールを AIP に送ってもらいました(もっと長いですが)。
2023/3/14
AIP から返信が届き、初めて「internal meetings」の情報が届きます。またこれは穿った見方かもしれませんが、エディターからメールを入れたおかげか、翌週に次回会議が開催されるとのことです。都合よく見えます。
While we are unable to provide a timeline for when a particular case will be resolved by as they are delicate matters, I can confirm that we have made great progress in working towards closing this case.
We hold internal meetings to work on our open investigations, the next of which is to be held next week. We will present the information you kindly supplied below at this meeting and aim to provide you with a status update afterwards.
We sincerely appreciate your patience and understanding throughout this process as we work to adhere to the ethical standards and processes of the Committee on Publication Ethics (COPE), of which AIP Publishing is a member.
2023/3/30
こちらから催促していないのに、初めて AIP から自発的にメールが来ました。エディターを巻き込んだ効果は絶大ですね。剽窃された側からの要求にはろくな対応をしてくれないのにです。
I’m writing to provide you with an update that, due to a postponement, our internal meeting is now to be held this week. After which, we will aim to follow up with you.
2023/3/31
また催促していないのに翌日に AIP から連絡が来ました。Chief Publishing Officer までエスカレートするとのことです。いやいや、Chief Publishing Officer まで上がってすらいなかったんですねという驚きです。
The findings of our investigation are now being escalated to our Chief Publishing Officer for review.
We will provide you with another update when a decision has been finalized.
2023/5/2
ここでまた AIP からの連絡が途絶えてしまっていたので、今度はエディターが AIP に催促のメールを送ってくれました。Chief Publishing Officer が進捗報告を寄越さないのは同じ悪行である、というような内容です。
2023/5/4
AIP から返信です。蕎麦屋の出前のようなメールが続きます。
Our investigation is nearing its conclusion and we will keep you informed of the outcome.
4. 論文撤回、感動のフィナーレへ
2023/5/6
AIP からついに論文撤回の決定のメールが届きました。
I am writing to inform you that as a result of our investigation, we will be retracting the following article: XXX https://doi.org/YYY
I will follow up with you when this retraction has been finalized.
2023/5/11
AIP のウェブサイト上で論文撤回(retract)が公開されました。
This is to inform you that this retraction has been published online.

5. 雑感
2021 年 7 月に問い合わせをし、4 ヶ月の完全放置、2021 年 11 月に再問い合わせをして 2023 年 2 月までこちらに分かるような進捗なし。複数回の問い合わせにもまだ時間がかかるという返事のみでした。ここまで 1 年半を(少なくともこちらから見て)進捗なしで終えました。
AIP Publishing はうちの業界でもプロシーディングスなどで使われている出版社であり大手です。このような出版社が論文剽窃の被害にあった側の申立てに対して十分な対応や状況説明をせず、またプロシーディングスのエディターにすら連絡を入れていなかったというのは驚くのを通り越し、呆れるほかありません。自分が直接関わる仕事であれば、AIP Publishing は二度と絡みたくないと思うのに十分でした。
2023 年 3 月にエディターを巻き込んでもらってから、結局 2 ヶ月で論文撤回に持ち込めました。1 年半の進捗なしとは大違いです。
たまたま論文撤回の最終局面にエディターの登場が重なっただけなのかもしれませんが、その後の AIP からの自発的なメール対応を見ても、エディターを巻き込んだことで事態が進んだと自分は想像しています。偉い人を巻き込むというのは大切ですね。
それと、問い合わせを開始する初期の頃に所属する名古屋大学の研究協力課に「剽窃をされる側になったのだが、名大として何かやることがあるか?」と尋ねたのですが、被害側になった場合は研究者個人で対応してくれとのことで、それが名大所属の論文だろうがなんだろうが、名大としては特に動いてくれないとのことでした。残念なことです。
6. Elsevier の対応(追記)
後から思い出しましたが、2021/11/30 に論文 B の copyright を有する Elsevier にも問い合わせをしています。「AIP には既に連絡済みだが、論文 B の copyright は Elsevier なので何かそちらがやることはあるか」という内容です。このような問い合わせをする直接の窓口が見つからなかったため、著作権等の扱いをしている Elsevier's Permissions Helpdesk というところにウェブフォームから送信しています。
翌日の 2021/12/1 に「Senior Copyrights Coordinator」という担当者から「Ethics Expert Team」に次の短文とともに問い合わせが転送されました。
Would you please assist with the below plagiarism query.
その後 Elsevier からも返信が特にないので 2022/1/25 に状況を尋ねるメールを返信したところ、
This email address is no longer monitored
という自動返信メールが届き、もう面倒くさいので Elsevier はほったらかしにしました。
国際会議のインフラ整備(GitHub Pages、Jekyll、ドメイン、メール)
宇宙線物理学および高エネルギー宇宙物理学の大規模国際会議(1000〜1500 人規模)が 2023 年 7〜8 月に開催されます。その運営業務でウェブサイトの構築(GitHub Pages と Jekyll)、独自ドメイン、独自ドメインの電子メール、および一斉メール配信の設定を色々とやったので、その備忘録です。
ドメインの取得
過去の同様の国際会議では .org を取得する(ircr2019.org など)、もしくは開催地の大学のドメインで運用する(icrc2021.desy.de など)の 2 通りが一般的でした。永続性という観点では後者のほうが良いのですが、後者であっても既に消えてしまっているウェブサイトもあるため、結局はそのサイトを記録として維持する気が運営側にあるかどうかで決まります。
「短いほうが格好いいし、デザインの際も楽だろ」ということで icrc2023.org を取得しました。ドメイン取得はそこまで大きな金額ではなく、また携帯電話の料金比較と同じで比較するのに情報を精査するのが面倒な類のものですので、特に思い入れもなく「お名前.com」(GMO)でドメインを取得しました。
3 年分のドメイン登録料:4,180 円(2021 年 3 月契約時の金額)
大学のサーバーではなく独自ドメインを取得して良かったのは以下の点です。
- icrc2023.org という短い URL へのアクセスを www.icrc2023.org へ転送させられる
- URL が短いため QR コードが単純なもので済む
- 先述の通り、ポスターなどのデザインが煩雑にならない
- コロナ対応の関係で開催地が大阪の民間会場から名古屋大学に変更になったものの、ドメインに開催場所の情報がないため、そこは気にならなかった
- 問い合わせ窓口をどの大学のメールサーバーで運用するかを考えなくて済む
- 問い合わせ窓口を複数用意するときに info@icrc2023.org、admin@icrc2023.org のように @ の前を変更するだけで済む(独自ドメインではない場合、icrc2021@desy.de などになる)
さて、ドメインを取っても何も起きません。ウェブサーバーを用意して、メールサーバーを用意して、ようやくそれで https://icrc2023.org を公開できるようになったり、info@icrc2023.org という問い合わせ窓口を用意できるようになります。
独自ドメインでの電子メール運用
基本的な方針として、物理的なサーバーの管理は一切やりたくありません。また大学の用意するサーバーも計画停電があったりするので使用したくありません。加えてサーバー管理なんて自分は最近すっかりやっていませんし(昔は大学院生が研究室のサーバー管理をする文化があった)、現代の知識にも追いついていません。
そうすると当然ですが大学外のサービスを利用することになります。ドメイン取得時に GMO を選択する際は電子メールの運用はちゃんと考えていなかったのですが、後日 GMO の「お名前メールライト」を利用することにしました。
お名前メールライト:242 円/月(1143 円/年)(2023 年 1 月までは 240 円/月)
ただし、ウェブサイト立ち上げ(2021 年 3 月頃、会議本番の 2 年以上前)の時点では管理者と問い合わせ窓口の 2 つ(admin@ と info@)しか使用しておらず、またメールも滅多に届きませんでしたので、初期には月額 110 円のメール転送サービスを使用していました。
お名前メールライトはディスク容量 2 GB しかありませんが、国際会議の問い合わせ窓口では添付ファイルはあまり扱いませんので、これで十分です。お名前メールライトは既に新規受付が終了しており「お名前メールスタンダード」(270 円/月、1260 円/年、20 GB)に移行しているようです。
実行委員会内部でのメーリングリストは東大宇宙線研のメールサーバーを使用しています。お名前メールライトでも作れるはずですが、試していません。
※ 関係する DNS の設定は後述。
最初は問い合わせ窓口ごとにメーリングリストを作ろうかと思ったのですが、担当者を追加する作業が面倒なこと、返信担当者のメールアドレスを表に出したくなかったこと、複数の担当者が入れ替わりながら同じメールアドレスで同じ質問に対応し続けられることなどの点から、info@ のような問い合わせ窓口用のメールアカウントを担当者複数人で共有することにしました。
これであれば IMAP を複数人で同時に見にいけますし、返信を複数人で行えますし、メッセージのスレッドにフラグを立てれば(Apple Mail の機能?)どの問い合わせに対応中か、対応済みかを可視化することもできます。ただし不便な点があって、誰かがメッセージを既読にすると IMAP 共有ですので他の人のクライアントでも既読扱いになってしまいます。そのため、担当者が複数人いる場合に他の担当者が新規受信に気が付きにくいという問題がありました。
メール一斉配信
国際会議では参加者や過去の参加者、もしくは興味のありそうな同業者にいわゆるサーキュラー(circular)というものを送ります。これは会議の開催通知や参加登録締め切りなどの重要事項の通知に使われます。今回の国際会議 ICRC2023 の場合にはおよそ 2000 名にメール配信をするのですが、最近は大学や学会の運営するメーリングリストでは Gmail などで弾かれる事例が頻発しているため(詳細は DKIM や SPF などで検索)、メール一斉配信サービスを利用することにしました。
これも同じく GMO のやっている「お名前.com メールマーケティング」というものを契約することにし、最大 3000 人にまで配信可能な「MM3000(12 ヶ月)」を申し込みました。これであれば、DKIM や SPF などの送信ドメイン認証で問題の発生する可能性は低いはずです。
メールマーケティング MM3000:21,725 円/年
これはそこそこ金額が行きます。値段の割には使い勝手が悪く英語対応もしておらず設定画面が 10 年前くらいの設計なのですが、メルマガの運営など営利目的で使い続けている人が多いのか、この金額と仕様でも他社と競合しないもんなんですね。
※ 関係する DNS の設定は後述。
ウェブサイト
基本的な要求仕様は、セキュリティ上の問題が長期発生しにくいもの、デザインの無料テーマで使いやすそうなものが無料もしくは低価格で転がっていること、名簿などのテキストファイルの自動整形などが簡単に行えること、公開後にメニューやページの追加などが簡単に行えること、です。
自分の研究室で Jekyll を使っていたこともあり、静的な HTML を生成可能で、かつ GitHub で履歴を辿ることのできる(実際に履歴を辿ることはまずありませんが)Jekyll と GitHub Pages を使用することにしました。一般的には WordPress などの CMS を使うことが多いと思います。しかし例えば International Scientific Program Committee(ISPC)や Local Organizing Committee(LOC)の名簿情報を更新するときに、WordPress の編集画面でテーブルを操作するなんてのは経験上やりたくありません。またページや記事の更新は Emacs でやりたいので、Jekyll のように markdown から静的 HTML を生成するものがありがたいわけです。
静的 HTML の生成という方針にすると(WordPress でもできるはずですが)、長期のセキュリティを気にする必要がなくなります。国際会議が終了しても 20 年程度はそのウェブサイトを記録として維持することもあるわけですし、また後日編集することもあるでしょうから、WordPress のようにログインが必要で、また内部構造を全て把握するのが大変なものは使用するのが躊躇われます。
また、GitHub Pages であれば無料でウェブサイトを公開することも可能であり、Jekyll で作成・編集したファイルを GitHub のレポジトリに commit するだけですぐに公開できます。国際会議の場合はアクセス数は特に大きくないですが、世界中からアクセスしても遅延時間が小さくするためには、やはり大学のサーバーではなく各地に分散しているものが望まれます。
ということで、markdown で書いた記事や YAML で作成したデータファイルを Jekyll で静的 HTML に変換し(GitHub Pages に変換させ)、それを GitHub Pages で公開することにしました。ただしそのままだと github.io のドメインになってしまうため、後述する DNS 設定で www.icrc2023.org で公開するようにしました。
GitHub Pages:無料
さて、肝心の成果物はこれです。
www.icrc2023.org
デザイン関係で利用したのは主に次のものです。
- Bootstrap 4 https://getbootstrap.com
- Material Kit 2.0.7 https://demos.creative-tim.com/material-kit/
- Material Icons https://fonts.google.com/icons
- Myriad Pro(Adobe Fonts)
- tmc(ロゴ、バナー、全体デザイン) https://www.tmc-creative.jp
Bootstrap 4:無料
Material Kit 2(Bootstrap テーマ):無料
Adobe Fonts:自分の業務用 Adobe CC に含まれる
tmc のデザイン費用:うん十万円
デザイン会社である tmc に国際会議のロゴと名古屋城などのデザイン製作を依頼しました。ウェブサイトのデザインを tmc が行う場合、通常はデザインをもとにしてウェブ製作会社に仕事が回り WordPress などのテーマを作成してもらうことになります。しかし Jekyll のテーマを作れる業者なんて見つかりませんので、違う方針を取りました。
まず Bootstrap 4 と Material Kit を使用して「構造としてはこんな感じの作りになります」というのを tmc に渡し、それに基づいて tmc がバナーを作成しフォントやウェイト、メニュー部分などで使用する基調色の決定をこちらに指示します。この指示書は Adobe Illustrator で作成されており HTML も CSS も関係ありませんが、それに基づいて自分が Material Kit の CSS や Jekyll の内部構造を修正するという作業を行いました。
HTTP から HTTPS への転送は GitHub Pages の設定から Enforce HTTPS を選べば自動で行われます。また icrc2023.org への www.icrc2023.org への転送も自動で行われます。
DNS レコードの設定
お名前.com の「ドメインの DNS 設定」
お名前.com の「DNS レコード設定」のページで以下の内容を登録します。
| ホスト名 | TYPE | TTL | VALUE | 優先 | 状態 |
|---|---|---|---|---|---|
| icrc2023.org | NS | 86400 | 01.dnsv.jp | 有効 | |
| icrc2023.org | NS | 86400 | 02.dnsv.jp | 有効 | |
| icrc2023.org | NS | 86400 | 03.dnsv.jp | 有効 | |
| icrc2023.org | NS | 86400 | 04.dnsv.jp | 有効 | |
| icrc2023.org | A | 3600 | 185.199.108.153 | 有効 | |
| icrc2023.org | A | 3600 | 185.199.109.153 | 有効 | |
| icrc2023.org | A | 3600 | 185.199.110.153 | 有効 | |
| icrc2023.org | A | 3600 | 185.199.111.153 | 有効 | |
| form3.icrc2023.org | CNAME | 3600 | form3.maildeliver.jp | 有効 | |
| redirect3.icrc2023.org | CNAME | 3600 | redirect3.maildeliver.jp | 有効 | |
| www.icrc2023.org | CNAME | 3600 | icrc2023.github.io | 有効 | |
| icrc2023.org | MX | 3600 | mx20.gmoserver.jp | 10 | 有効 |
| icrc2023.org | TXT | 3600 | google-site-verification=XXX | 有効 | |
| icrc2023.org | TXT | 3600 | v=spf1 include:_spf.maildeliver.jp ~all | 有効 | |
| maildeliver._domainkey.icrc2023.org | TXT | 3600 | v=DKIM1;k=rsa;t=s;p=YYY | 有効 |
なんだかよく分かっていませんが、理解の範囲で(未来の自分に)解説。
最初の 4 つ、0X.dnsv.jp の NS レコードは、そこに行くと icrc2023.org の IP アドレスは何かを教えてくれます。ここはお名前.com のユーザー自身では変更できない設定項目です。
次の 4 つ、185.199.1XX.153 はホスト名と実際の IP アドレスの対応関係ですね。この 185.199.1XX.153 は GitHub Pages の WWW サーバーです。これは GitHub Pages の解説にそう書いてあるので、そう設定しました。例えば www.icrc2023.org に ping を打つとこれらの IP アドレスが応答するようになります。
docs.github.com
GitHub では現在プライベート設定ですが、ICRC2023/icrc2023.github.io というレポジトリを登録しています。
https://github.com/ICRC2023/icrc2023.github.io
外部ドメインを使用しない場合、この中身は https://icrc2023.github.io で公開されます。しかし custom domain の設定を GitHub Pages の設定で www.icrc2023.org で追加しているので、185.199.10X.153 を A レコードに追加することで、この GitHub 管理下の WWW サーバーに接続してくれるようになるわけです。
その次の form3.maildeliver.jp と redirect3.maildeliver.jp の 2 つは、一斉メール配信の配信登録・解除用のページが用意されるサーバーと、メール中のリンクを踏んだかどうかのアクセス解析をするためのリダイレクトサーバーです。前者は新規にメール配信を望む同業者(特に最近大学院生になったような人たち)および配信をもう望まない同業者(研究職を離れてしまったような人たち)に向けて必要です。後者は国際会議だとどうでもいいです。設定はしていますが使っていません。Google Analytics も利用していますが、それを見てどうこうするわけでも一喜一憂するわけでもありません。
そして icrc2023.github.io の行は、www.icrc2023.org の実際の中身は icrc2023.github.io で公開しているからそれを見に行ってねということです。
mx20.gmoserver.jp の行は、icrc2023.org 宛のメールを実際にはどのサーバーに送れば良いかの設定です。icrc2023.org 自体は専用のメールサーバーを物理的に持っているわけではなく、裏では「お名前メールライト」が GMO のサーバーで動いているわけです。したがって、icrc2023.org に届いたメールは GMO のこの mx20.gmoserver.jp で処理されることになります。
google-site-verification の行は、自分のドメインで Google Analytics や Search Console を使うときに必要な設定です。Google Analytics を埋め込んだサイトが確かに自分のアカウントのものであると確認する役割を果たします。XXX の部分はユーザーごとに異なる長い文字列です。
そして最後の 2 つが、「お名前メールライト」の設定で必要な項目です。SPF と DKIM の設定をすることで送信元サーバーの認証が行われるため、受信サーバー側でスパム判定される可能性が下がります。この 2 つの設定項目は、「メールマーケティング」のコントロールパネルの「DNS 設定情報」に記載があるのでこれをコピペしました。YYY はユーザーごとに異なる長い文字列です。
お名前メールライトの「独自ドメイン設定」
さて、お名前メールライトのほうでも DNS の設定をする必要があります。この設定はメールマーケティングと併用するユーザーはやる必要があると電話窓口で説明を受けましたが、自分はなんだかよく分かっていません。
| ホスト名 | 指定先 | レコードタイプ | 優先度 | ポート | 重さ |
|---|---|---|---|---|---|
| (なし) | 185.199.108.153 | A | |||
| www | icrc2023.github.io. | CNAME | |||
| ftp | 標準 | A | |||
| (なし) | 標準 | TXT | |||
| form3 | form3.maildeliver.jp. | CNAME | |||
| redirect3 | redirect3.maildeliver.jp. | CNAME | |||
| maildeliver._domainkey | v=DKIM1;k=rsa;t=s;p=XXX | DKIM(TXT) | |||
| (なし) | google-site-verification=YYY | TXT |
最初はこの辺りの設定を空欄にしていたのですが、info@icrc2023.org などからメールを送信すると Gmail に弾かれる場合があったので電話窓口で相談したところ、ここでも設定しないと SPF 認証が有効にならず spf=softfail という結果が Google から返ってきてしまいます。
ただし、ここの設定には SPF の設定があるわけではなく、また DKIM の設定をここでしていても info@icrc2023.org などからのメールには DKIM 関係のヘッダーが存在せず SPF のみが存在します。メールマーケティングの一斉配送の場合には、SPF も DKIM もヘッダーに書き込まれます。
出張の持ち物 2022 年版
2018 年版が古くなったので更新。
国内・海外出張共通
国内出張
- (物理学会のとき) 名札
海外出張
- パスポート
- e-ticket の印刷と PDF
- 現地の Google Maps の offline map
- ワインケース
- ヨーロッパ用 Mac の AC ケーブル
- ヨーロッパ用のコンセントアダプタ
- 現地通貨
- 銀行の海外出金用カード
オイスターカード(London の場合)クレジットカードのタッチ決済で良くなった
コロナ関係
長期海外出張
観測シフト
- 登山靴
- 山頂用の服装
波物語クラスターのまとめ
波物語について
愛知県常滑市で「NAMIMONOGATARI2021」(以降、波物語)という野外音楽フェスが 2021 年 8 月 29 日に開催されました。報道によれば、緊急事態宣言下で 7392 人の参加者があり、会場での酒販・飲酒、一部参加者のマスク非着用が認められ、また参加者同士の距離を十分に取らない身体接触や出演者も煽る形での声出しが行われました。
陽性者とクラスター
愛知県等の発表資料によると、波物語に関係する新型コロナウイルスの陽性者は、9 月 19 日現在で 47 名です。この内訳は次の通りです。
- 愛知県がクラスターとして認定し発表した「イベントクラスター(10L)」:27 名
- 愛知県と名古屋市が実施した、無症状(自己申告)の参加者に対する無料 PCR 検査(検査キットの郵送)
- 愛知県実施分(351 検査):4 名
- 名古屋市実施分(307 検査):4 名
- 愛知県外陽性事例
- 岡崎市在住の参加者から拡大した事例:2 名
- 上記の合計 = 27 + 4 + 4 + 3 + 3 + 1 + 2 + 1 + 2 = 47 名
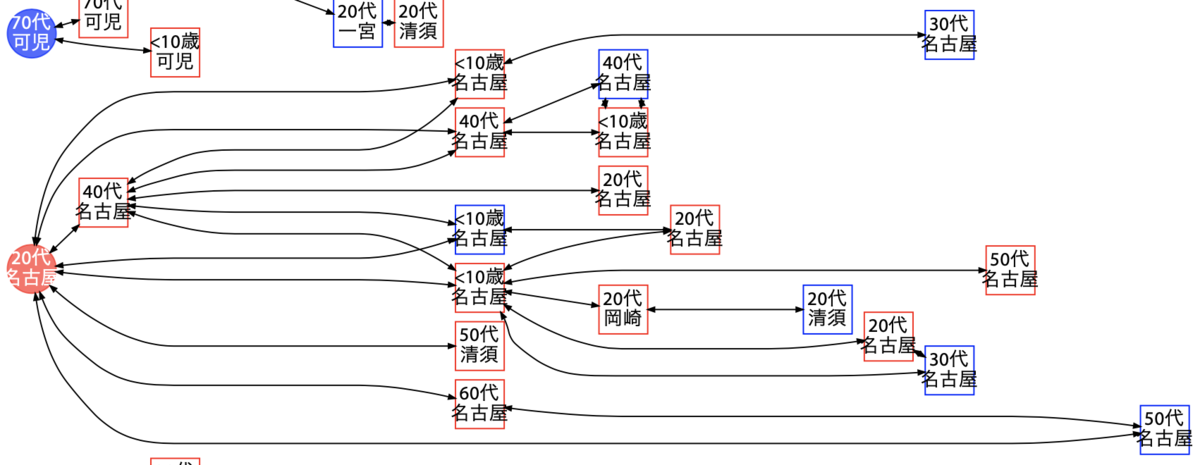
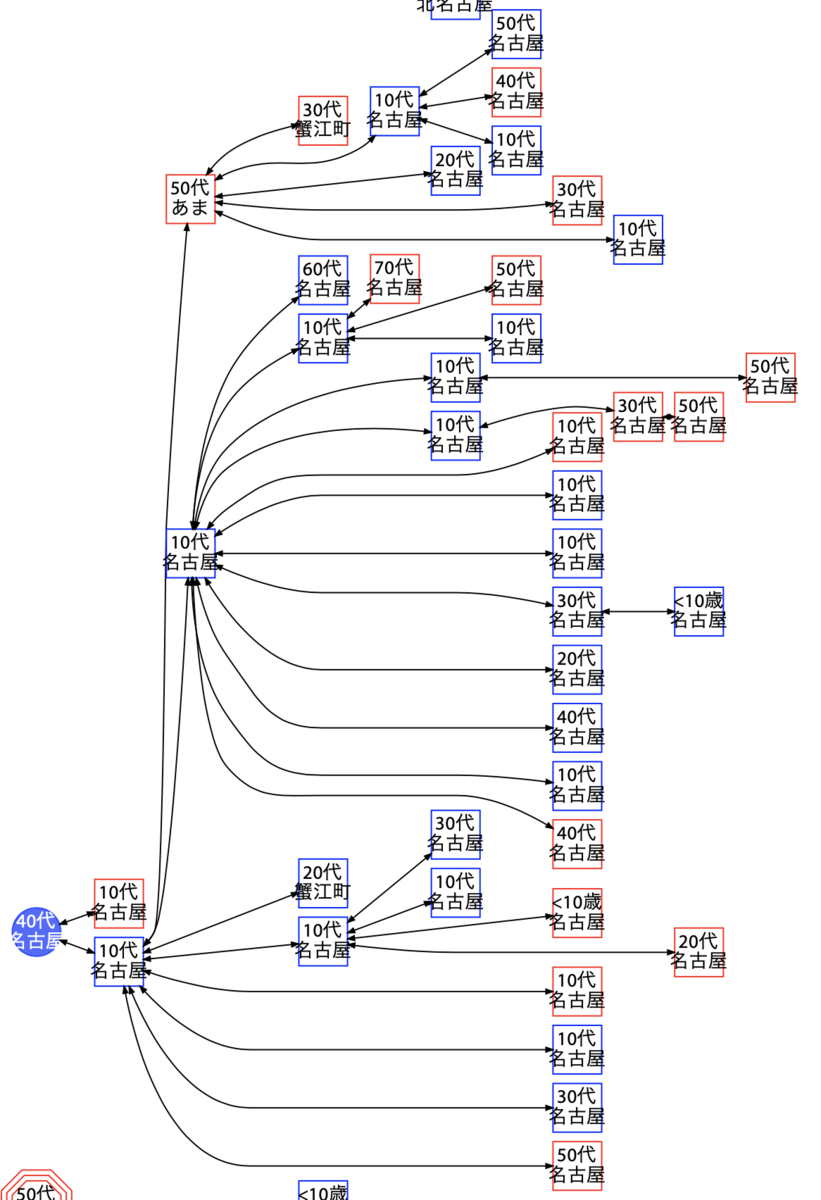
このうち、クラスター(10L)の 27 名、および岡崎市 10 代男性から同居家族(岡崎市 40 代女性、同 10 代男性)への拡大を 1 つの経路図として図示したものが、次の図です。

ここで注意したいのが、名古屋市管轄や愛知県管轄の陽性事例は接触経路が 8 月から非公表になったということです。そのため、岡崎市・豊川市・豊橋市・豊田市以外に居住する事例の場合、接触経路は不明です。つまり、仮に 2 次感染があったとしても、それが明らかになるのはこの図では岡崎市事例と豊橋市事例のみになります。
この図では岡崎市・豊橋市在住者は 3 名だけですので、大雑把には 3 分の 1 の確率で(保健所の追跡可能な)2 次感染が発生すると言えます。単純計算で 27 名中 9 名が 2 次感染をさらなる 2 名に起こしていたとすると、2 次感染の人数は 18 名程度と推測できます。
また、愛知県は単にクラスター 10L とだけ公表しておりその中でどのような接触経路が存在したかまでは公開していないため、先頭の稲沢市 20 代女性が全員に感染させた、いわゆるスーパースプレッダーであったという意味でもありません。感染日と、発症・受診・検査の時期は人によって異なります。あくまでこの図は陽性判明の時系列を表しているにすぎません。
この感染経路図の作成方法については、愛知県・岐阜県の感染経路図を可視化した際に書いた記事を参照してください。(この頃はまだ 329 事例でしたが、結局愛知だけで 10 万事例を超えたのにまだ継続しています。)
oxon.hatenablog.com
oxon.hatenablog.com
愛知県が通常「クラスター」として認定し公表するのは、次の条件を満たしている場合だと考えられます。
- 同一の場所で発生していること(家庭での拡大など、2 次感染は含まない)
- 感染者同士の接触経路が追えていること(濃厚接触が確定もしくは、職場の同僚など接触した可能性が高い)
- 合計で 10 名以上であること
※ ただし、豊橋市の高校でかなりの生徒に感染が広がった事例は、同一時間、同一場所ではないということでクラスター認定されなかった。
※ また、保健所の基準で濃厚接触ではなく接触が疑わしい程度だと、同じ職場で 10 名を超えていてもクラスター認定されない場合がある(例えば愛知県内の最初のデルタ株事例は職場感染を含め合計 26 名までの拡大が追跡されたが、職場内での接触経路は公開されずクラスター認定もなかった)。
しかし、この波物語クラスターは本当に愛知県がこれまで採用してきた「クラスター」の定義に合致するかは怪しいところです。27 人もいて、接触を辿れる同一のグループ行動を音楽フェス内でしていたとは考えにくいと思います。実際、愛知県外の事例は大規模な人数ではなく、またこの 27 人の居住地もあまりにバラバラです。
9 月 2 日の稲沢市の 20 代男性は稲沢市の消防士であることが報道から分かっており、この方は友人 2 人と参加したと発表されています。したがって、この 27 人はいくつかのグループに分割するのが自然であり(会場で同じ日に感染したものの、互いに接触していない複数のグループに分かれる)、愛知県がこれまで「クラスター」と呼んでいた形態とは異なるのではないかと思います。
また時系列を追ってみると分かりますが、稲沢市在住者 4 名が先頭に固まっていること、9 月 10 日の東海市事例は当初、経路不明(塗り潰し)として公表されていたこと、後半は名古屋市在住者が多数を占めることなどから、この「クラスター」と愛知県が呼んでいるものは、会場内で同時多発したいくつかの小規模クラスターなのではないかと自分は推測しますれます。またもし普段から行動をともにしている友人同士だった場合、たまたま波物語の開催時期に重なっただけで、その前からもしくは事後に友人同士で感染していた(した)可能性もあります。
リスク評価
2 次感染は無視したとして、7392 人の参加者のうち判明しているだけで 45 名の陽性事例が 14 日間にわたり発生したことになります。愛知県の 10〜20 代人口は約 150 万人です。また 9 月 1〜14 日の期間における愛知県内 10〜20 代の陽性事例は 6777 事例(10 代 2456、20 代 4321)です。したがって、これまた非常に単純な計算をすると (45/7392) / (6777/1500000) = 1.35 倍の確率で波物語は陽性事例が発生しやすい状況であったということになります。クラスターとして認定されていなかったり、参加した旨を申告していない感染者も実際にはいるでしょうから、多めに見積もって約 2 倍だと考えましょう。
これを多いと見るか、それとも大したことないと考えるかは、ちょっと難しいところです。(完全に偏見と、自分自身のクラブに行ったりしていた 20 年前の経験ですが)そもそも波物語の客層は新型コロナウイルスに感染しやすい交友関係を持っていた可能性があります。つまり、波物語に参加しなくても、遅かれ早かれどうせ友達同士で感染していたであろう人たちが、波物語をきっかけに感染した可能性があります。
例えば名古屋大学の学生数は約 15000 人ですが、このうち 9/1〜14 の期間で大学から公表された感染者数は 4 名です。上述の愛知県内 150 万人の 10〜20 代の感染事例 6777 と比較すると、10 分の 1 程度の発生頻度でしかなく、新型コロナに感染しやすい層としにくい層がいるのは明らかです。
波物語だけを敵視しなくても、4 人程度の若者同士の会食は愛知県内で 2000 回よりは桁で多く発生していると思われ、そのような場は県内全体の平均的な感染確率よりも高い環境であり、第 5 波の感染拡大に圧倒的に寄与しているはずです。
もちろん野外音楽フェスでもライブでも感染対策をするに越したことはありません。しかし「自粛の要請」という意味の分からない日本語を行政が振りかざし、特定のフェスにだけ愛知県知事が検証委員会を作って槍玉にあげるのは、「やっている感」を出したり怨嗟の吐口にするだけであって、日本全体、愛知県全体の感染拡大防止としては効果が薄いのではないかと思います。
この大雑把な計算で野外音楽フェスのリスク評価をするのは難しいですが、愛知県内全体の感染に比べて特に問題視するようなことではない、というのが自分の印象です。もっと定量的な評価は愛知県や国がしっかり行う必要があると思います。(感染拡大自体を自分は問題視しているので、波物語が感染防止対策を徹底しなかったのは問題視されるべきだが、波物語だけを攻撃するのは違うのではないか、ということです。)
計算間違いや、より定量的な評価方法などがあれば、ご指摘ください。
子供(10 歳未満)の感染経路はどうなっているか、20000 件超の感染経路図から考える
背景
4 月から開始した愛知・岐阜における新型コロナ感染経路の可視化は、既に報告件数 20000 件超を扱うようになりました。
このうち会食や職場など様々な感染経路が存在しますが、10 歳未満の子供の新型コロナの感染経路の実態はどうなっているのか。より個人的な観点からは、我が家の子供達が小学校や保育園で感染してくるか、また家庭内感染へと広がりうるのか。そういうことを実際の感染事例から概観してみたいと思います。
※1 この記事に書く内容は、あくまで愛知県、名古屋市、豊田市、岡崎市、豊橋市、岐阜県、岐阜市の公開データに基づきます。そのため、症例の詳細や保健所や当事者しか知らない感染経路の本当のところは分かりません。
※2 これは医療関係者でも感染症の専門家でもなんでもない、素人の blog 記事です。
※3 10 歳未満に限っているのは、10 代を含めると(公開データが年代別になっており)18 歳以上の行動パターンと区別が困難になるためです。
国民の多くに新型コロナ対策が浸透し、それでもなお第 3 波が愛知県で広まり始めたのは 2020 年 10 月中旬のことです。このうち、11 月 1 日以降の陽性報告で陽性者の年齢が「10 歳未満」「0 歳」「1 歳未満」となっている事例と、それら事例に接触者・濃厚接触者として関連づけられている事例のみで、全ての感染経路図を作成しました。
かなり巨大な PDF として GitHub に公開しています。「2021-01-08(愛知、10 歳未満の子供を含むクラスターのみを表示)」というリンクがそれです。
github.com
PDF への直リンクはこちらです。
https://github.com/akira-okumura/COVID-19/raw/master/PDF/Aichi2021-01-08_kids.pdf
保育施設におけるクラスター事例
さてこのうち、保育施設で発生した大きいクラスターは 2 件のみです。小学校では自分の知る限り報道に出る規模のクラスターは発生していません。
クラスター 3E
1 つ目は愛知県がクラスター 3E と呼んでいる名古屋市の保育施設で発生したもの。これは職員と思われる 20〜40 代の方々と、施設利用者である 10 歳未満の子供たちで構成されます。ここで、報告順が左から並んでいるからといって、先頭の方がウイルスを持ち込んだかのように解釈しないでください。感染日と発症日と陽性確定日は人によって前後するためです。また線が繋がっているからといって接触している、感染させた、とは限りません。多数の線が出ているからといって「スーパースプレッダー」というわけでもありません。
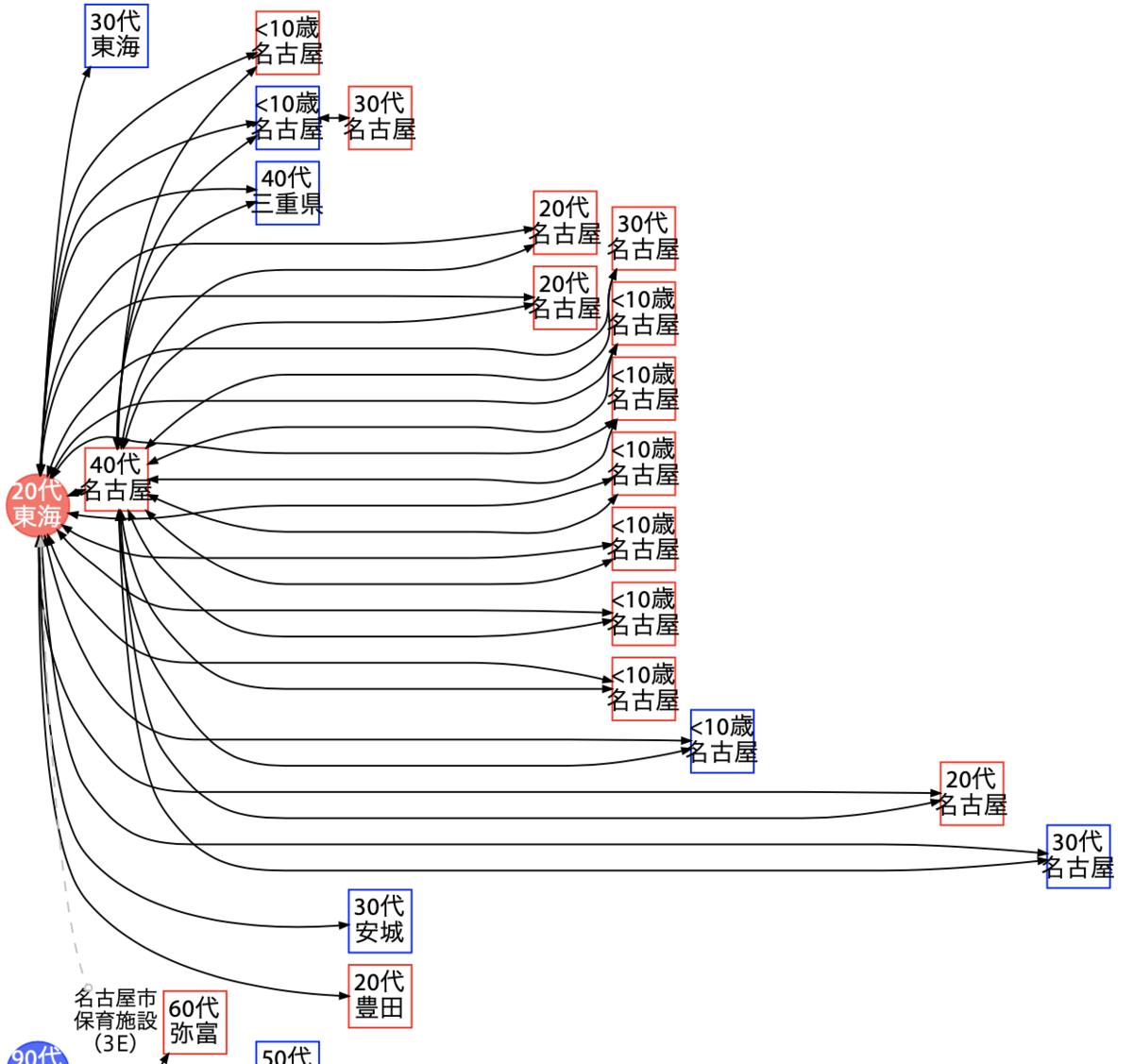
このうち、施設職員と母親(と思われる)に繋がっている子供は 9 名中 1 名のみですが存在します。すなわち、もし施設内でまず感染が広がり、その後この子供が家庭内感染を起こしたとすると、感染をある場所から他の場所へ広げていることになります。逆に家庭内で先に感染が起き、その後施設内でクラスターを発生させた可能性もありますが、その場合もやはり、10 歳未満の子供が他の場所へ拡大させる役割を持つことが分かります。
この図からは少なくとも感染の上流がどちらであったかは判断つきません。しかし 10 歳未満の子供(おそらく 6 歳以下)が感染を他の場所へ移動することは間違いありません。
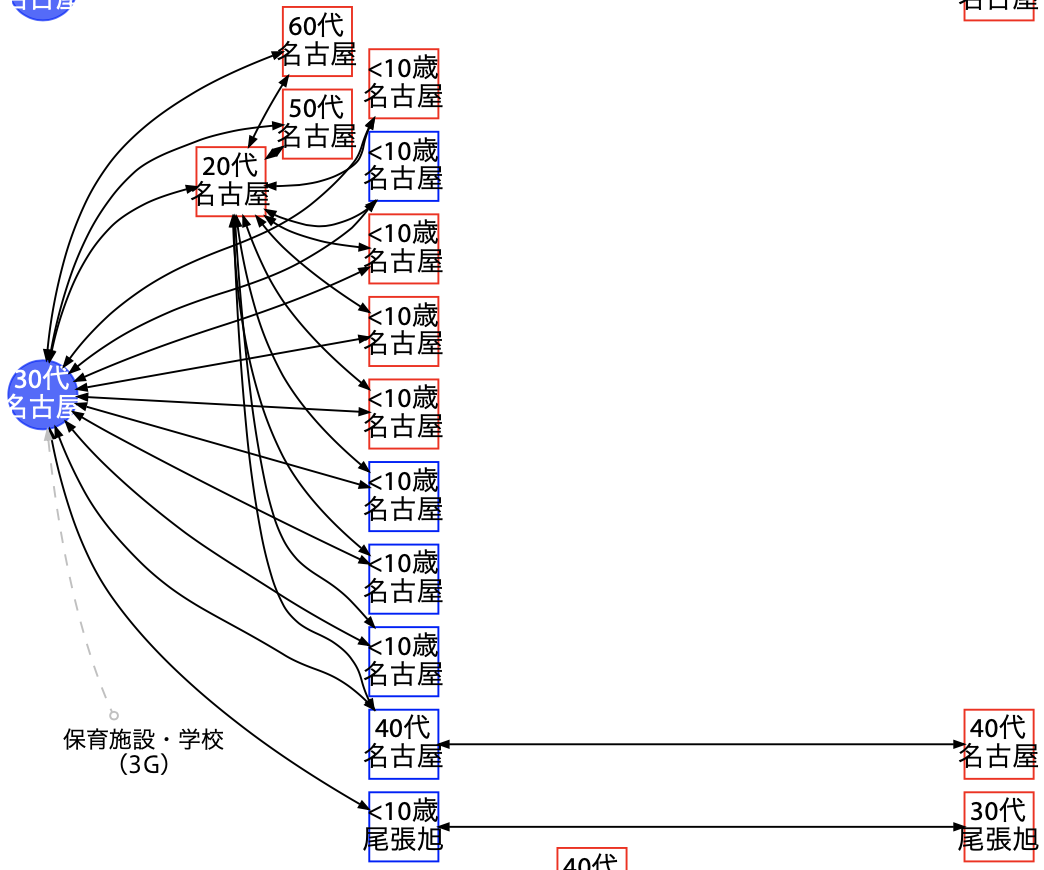
クラスター 3G
2 つ目は同様に名古屋市内の保育施設もしくは学校のクラスター 3 Gです。これも 3E と同様、20〜60 代の職員と思われる方々と子供たちで構成されます。ここでも 9 名の子供のうち 1 名は家庭内感染と繋がっているため、他の場所へと感染を拡大させる場合があることが分かります。
クラスター 3G と 3E から分かること、分からないこと
クラスター 3E と 3G の事例の子供たちは家族構成が比較的似通っている(30〜40 代の両親もしくは片親、兄弟姉妹など)と考えられるため、このような家族構成の子供 18 事例中、ウイルスを他の集団に移動させたのは 2 事例だと言えます。ただし、他の家庭でも感染は起きていたのに、無症状かつ PCR 検査にかからなかった可能性は排除できません。
それぞれの施設内でどのように感染が広まったかは明らかになっていないため、子供達が遊ぶときに互いにベタベタ触ったのか、それとも子供や職員の飛沫感染が起きたのかは分かりません。しかし、子供から家庭感染への拡大が起きにくいことを考えると、子供から職員へ移したという可能性は低いのではないかと思います。親子の接触に比べると、子供と職員の接触は薄いためです。
大垣日大高校
ここで、10 歳未満ではありませんが、飲み会による感染を起こさないと思われる高校生のクラスター事例も見てみましょう。
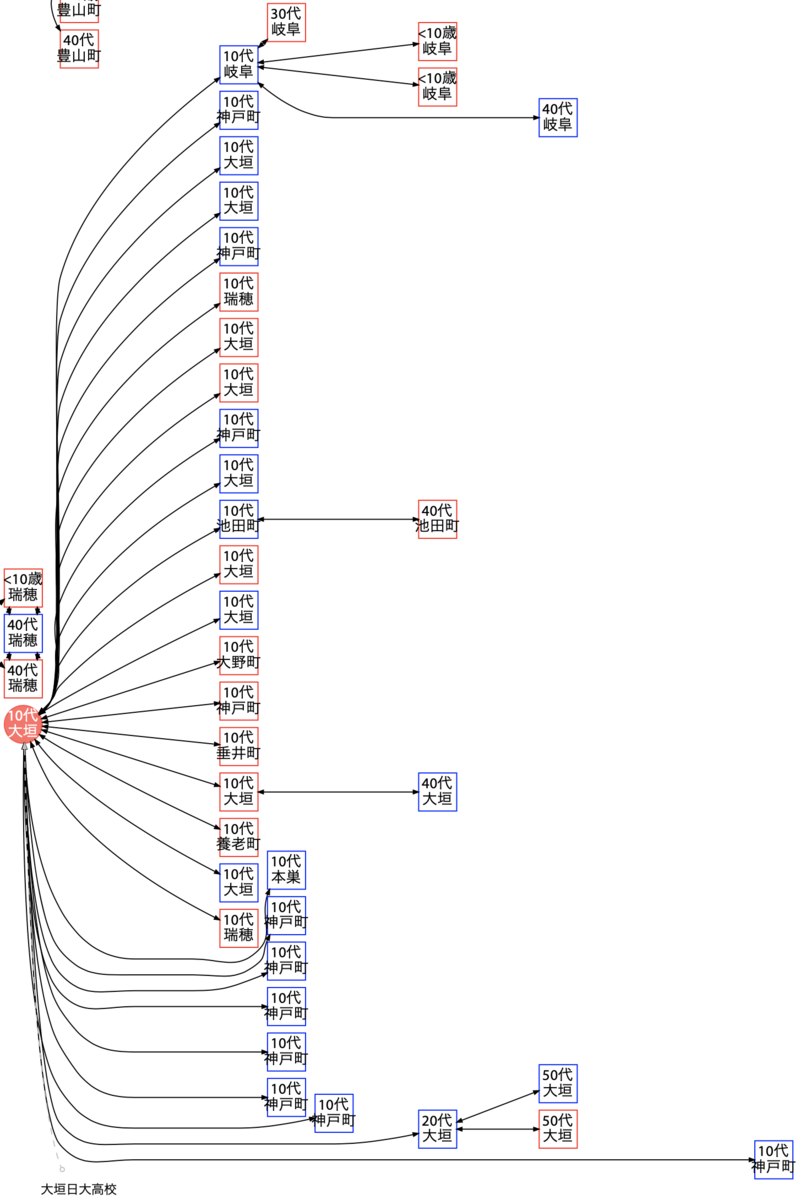
学校内でどのように感染が広がったかは報道にありませんが、高校生と思われる 10 代の 28 名のうち、家庭内感染は 4 件のみです。小さい子供に比べると親子の接触は減っていると思われますが(経験談)、3G・3E の 18 事例中の 2 事例と同程度の、28 事例中の 4 事例です。
ただし、このクラスターは全部で 45 名いるはずなのですが、岐阜県の公表データからは 38 名しか経路図として接続できることができませんでした。7 事例が家庭内感染もしくは他の生徒の事例として隠れているかもしれません。
子供から子供へ移したと思われる事例
こちらの事例は、おそらく最初の 4 名は 3 世代の家庭内感染(濃厚接触)です。最後の 10 歳未満の 2 名は、このうち真ん中の 10 歳未満の 2 名との「関連からの検査」として公表されています。「関連からの検査」という書き方は、その濃厚接触ではないが、その発生した集団内になんらかの形で属していた場合に使われる表現です。同居家族であれば「接触」や「濃厚接触者」として書かれる場合が多いはずです。
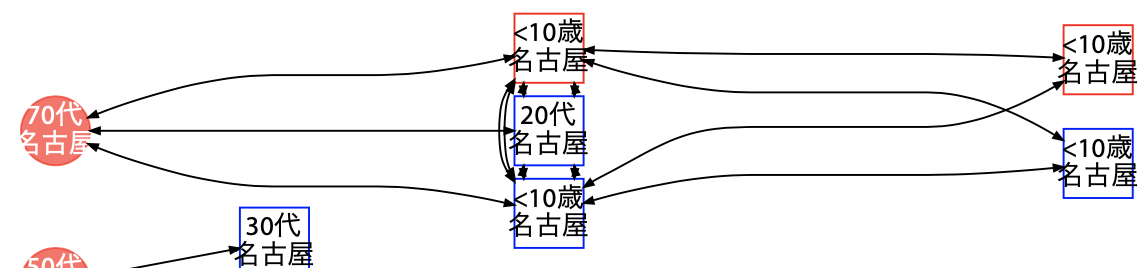
つまり、これら 4 名の 10 歳未満の子供たちは同じ集団に属しており、濃厚接触かどうかは追跡調査で判明しなかったものの、集団内で感染が起きたということです。その集団に大人がいるはずですが、大人への感染は確認されなかったと言えます。したがって、単純には 10 歳未満の子供同士で感染させ合う可能性があるということです。(インフルエンザでも学級閉鎖が起きるので当たり前ですが)
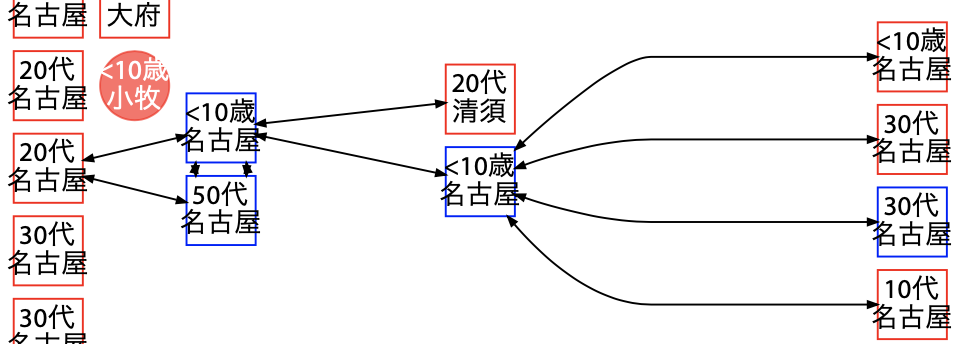
子供から複数の大人へ移したと思われる事例
こちらの事例では、中央の縦 1 列に 10 歳未満の子供が 3 名おり、これは先頭から繋がる何らかの集団(保育施設など)と思われます。
このうち 1 番下の女の子はこの左側の集団を含め 4 つの異なる大人へと繋がっています。つまり、4 つの集団のうちどれが感染の上流かは分かりませんが、子供を媒介として複数の集団へ感染を拡大させる場合もあるということです。
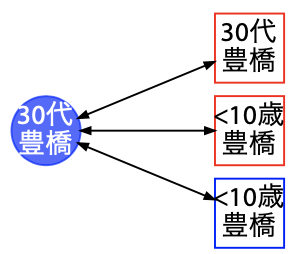
子供を 2 人経由して移したと思われる事例
こちらの例では、大人から子供に感染し、それが他の子供へ感染し、さらに大人へ移すという事例です。もし子供から大人は移りにくい、子供同士は移りにくいというのが事実だとしても、それらの低い確率を掛け合わせた事例というのも、これだけ感染者が増えてくると存在するということです。ただし稀です。
子供の感染の大部分を占める経路不明からの家庭内感染
多くの子供の感染事例のうち、頻繁に目にするのが感染経路不明の親(父親が多い)から家庭内感染をしたと思われる事例です。特にこれらの家庭(と思われる)を取り上げた理由はありませんが、典型例です。



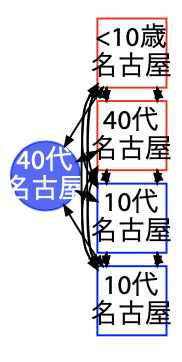
父親が外からもらってきたのか、母親がもらってきたのかは発症日と感染日に時間差があるため、これらの図では分かりません。ただし、傾向として父親が先に陽性確定する事例が多いということです。
大きなクラスターの末端に子供がくる例
現在、愛知県内、岐阜県内では様々なクラスターが発生しており、当然そのようなクラスターに含まれる大人の中には、小さい子供を持つ方たちも多くいます。そのような場合、クラスターの末端に子供がくるというのもたまに見かけます。
まとめ
当たり前ではありますが、子供から子供へも感染させる、子供から大人へも感染させる、そして大人から子供へ家庭内感染させたと思われる事例が圧倒的に多いということが確認できました。ここで取り上げた事例以外にも多数の経路が載っていますので、興味のある方は全体 PDF を眺めてみてください。
https://github.com/akira-okumura/COVID-19/raw/master/PDF/Aichi2021-01-08_kids.pdf
我が家の考え方としては、次の通りです。
- 親は家庭外で会食をしない、職場でも気を付ける
- 保育園も小学校も通わせないわけにもいかないので通わせる
- 子供がもらってきたら諦めるが、その発生確率は高くはない
- 子供は屋外で遊ばせ、他の家庭への訪問は避けてもらう
年末年始の帰省による、大都市圏からの新型コロナ感染者の流入実態(愛知県の場合)
2020 年の 4 月から愛知・岐阜の新型コロナの報告事例観察を継続しています。
oxon.hatenablog.com
さて、年末年始の帰省による人の移動で新型コロナが地方に広められてしまうのではないかという心配がありました。(発掘できなかったのですが)年末年始に診療にあたる医師が帰省してきた感染者の診察を何件かしているという Twitter の投稿も見かけました。
また実際、2021/1/5 の愛知県の発表では「東京などから年末年始に帰省して県内の実家で発症した例も複数含まれる」ということで、それが全国的な感染拡大にどのような影響を与えるのか心配なところです。
www.tokai-tv.com

そこで、2020 年 11 月以降の愛知県内の陽性報告事例のうち、住居地が愛知県・岐阜県・三重県以外の事例のみを抽出したのが上の図です。これを見ると、10〜30 代の大都市圏(東京都 + 千葉県 + 神奈川県、大阪府、京都府など)に居住する若者が愛知県内で発症する事例が、12/29 以降に突然、頻発するようになったのが分かります。年末年始の帰省によって、大都市圏から地方へ(この場合は愛知県ですが)新型コロナウイルスが拡散されるのが改めて確認されました。
| No | 発表日 | 年代・性別 | 住居地 | 接触状況 |
|---|---|---|---|---|
| 6353 | 11月3日 | 30代男性 | 東京都 | 10月31日まで東京都に滞在 |
| 8509 | 11月21日 | 40代男性 | 福井県 | |
| 13553 | 12月18日 | 50代男性 | 千葉県 | |
| 13564 | 12月18日 | 40代男性 | 沖縄県 | |
| 13759 | 12月18日 | 30代男性 | 東京都 | |
| 13795 | 12月19日 | 40代男性 | 千葉県 | |
| 13963 | 12月19日 | 20代男性 | 兵庫県 | |
| 14215 | 12月21日 | 40代男性 | 大阪府 | No.12325,12324と接触 |
| 14565 | 12月23日 | 50代男性 | 福岡県 | |
| 15285 | 12月26日 | 30代男性 | 石川県 | フィリピン |
| 15511 | 12月27日 | 50代男性 | 東京都 | |
| 15907 | 12月29日 | 20代男性 | 神奈川県 | |
| 16043 | 12月29日 | 50代男性 | 京都府 | |
| 16100 | 12月30日 | 30代男性 | 福岡県 | No.15711と接触 |
| 16389 | 12月31日 | 60代男性 | 東京都 | |
| 16422 | 12月31日 | 20代男性 | 東京都 | |
| 16618 | 1月1日 | 20代男性 | 東京都 | |
| 16722 | 1月1日 | 20代女性 | 東京都 | |
| 16724 | 1月1日 | 10代男性 | 京都府 | 京都府事例と接触 |
| 16766 | 1月1日 | 20代男性 | 東京都 | |
| 16825 | 1月2日 | 20代男性 | 大阪府 | |
| 16831 | 1月2日 | 20代女性 | 東京都 | |
| 16834 | 1月2日 | 30代女性 | 東京都 | 東京都事例と接触 |
| 16874 | 1月2日 | 30代男性 | 東京都 | |
| 16957 | 1月3日 | 20代男性 | 茨城県 | No.16295と接触 |
| 17112 | 1月3日 | 30代女性 | 東京都 | |
| 17137 | 1月4日 | 10代男性 | 北海道 | 北海道事例と接触 |
| 17138 | 1月4日 | 20代男性 | 大阪府 | 大阪府事例と接触 |
| 17321 | 1月5日 | 20代女性 | 東京都 | |
| 17337 | 1月5日 | 20代男性 | 大阪府 | |
| 17383 | 1月5日 | 20代男性 | 群馬県 | |
| 17402 | 1月5日 | 20代男性 | 東京都 | |
| 17404 | 1月5日 | 20代女性 | 東京都 | |
| 17458 | 1月5日 | 20代男性 | 千葉県 | 千葉県事例と接触 |
| 17521 | 1月5日 | 20代男性 | 東京都 | |
| 17768 | 1月6日 | 10代男性 | 福井県 | No.17216と接触 |
| 17802 | 1月6日 | 20代女性 | 京都府 | |
| 17804 | 1月6日 | 60代男性 | 静岡県 | |
| 17886 | 1月6日 | 20代男性 | 京都府 | |
| 17900 | 1月6日 | 30代男性 | 東京都 | |
| 17952 | 1月7日 | 20代女性 | 東京都 | |
| 18415 | 1月8日 | 20代男性 | 奈良県 | |
| 18642 | 1月8日 | 20代女性 | 東京都 |
少なくとも 1 月 8 日(発症日ではなく公表日)の時点でこのような事例が愛知県内だけで 30 件発生しています*1。愛知県人口が 750 万人で、多くの帰省を受け入れる県・道の人口がおよそ 10 倍の 7500 万人と見積もると、全国で同様の事例が 200〜300 件は発生しているのではないかと推測されます。多くの場合、帰省中に家族や旧友と飲食をしていると考えられるので、この 200 件に少なくない数がさらなる感染者数として上乗せされると推測されます。
このうちの 9 事例では、帰省中の愛知県内での接触により感染拡大が起きている可能性があります。
*1:ただし、そのうち 16110 と 16957 の 2 件は、帰省中に愛知県内で感染したと思われる。
Feynman Diagram が TeX Live 2019/2020 でちょん切れないようにする
TeX Live 2018 + Mojave の環境までは LaTeXiT で Feynman diagram を描くときは阪大の山中さんのページを参考にしていましたが、Catalina + TeX Live 2019 にしたら図がちょん切れるようになった(bounding box がおかしくなった)ので、解決する方法の覚え書きです。
詳細は StackExchange にも質問で書きました。
新しいやり方
latex+dvipdfは使わない(そもそも、dvipdfだと図が真っ白になる)dvipdfmにすると図がちょん切れるので、これも使わない- LaTeXiT の preamble に
\usepackage{feynmp}だけでなく\DeclareGraphicsRule{*}{mps}{*}{}も追加する mpostの実行後、pdflatexで PDF を出力させる


古いやり方だと \usepackage{feynmp} を追加するだけでしたが、これだけだと mpost コマンドの生成する拡張子なしの PS ファイルを pdflatex が正しく取り扱えません。そのため、古いやり方では latex と dvipdf を使って DVI を経由させていたのだと思います。
\DeclareGraphicsRule{*}{mps}{*}{} も追加することで、拡張子のないファイルを pdflatex が扱えるようになるので、TeX Live 2019 や 2020 で現れる dvipdf もしくは dvipdfm の問題(仕様?)を回避することができます。
古いやり方
TeX Live 2018 まで問題なかった山中さんのやり方で dvipdf を dvipdfm にすると絵は出てきますが、下がちょん切れていますね。

